
Lokale KI direkt auf Geräten verändert IoT-Systeme spürbar: Entscheidungen fallen schneller, Daten bleiben näher an der Quelle und die Abhängigkeit vom Netz sinkt. Genau das ist der Kern von ai at the edge: Modelle laufen dort, wo Sensoren, Kameras oder Gateways die Daten erzeugen, statt erst einen Umweg über die Cloud zu nehmen. Für Betreiber in Deutschland ist das besonders relevant, wenn Latenz, Datenschutz, Energieverbrauch oder schwankende Konnektivität den Alltag bestimmen. Ich zeige hier, wann sich der Ansatz wirklich lohnt, welche Hardware ich dafür wählen würde und wo die typischen Grenzen liegen.
Die wichtigsten Punkte auf einen Blick
- Lokale Inferenz senkt Latenz und macht IoT robuster, wenn die Verbindung nicht dauerhaft stabil ist.
- In der Praxis läuft meist nur die Auswertung auf dem Gerät, während Training und Flottenmanagement weiter zentral passieren.
- Quantisierung, Pruning und kleine Eingabedaten sind oft wichtiger als ein großes Modell mit vielen Parametern.
- Für Sensoren, Gateways und Industrie-PCs gelten unterschiedliche Anforderungen an Strom, Speicher und Wartung.
- In Deutschland spielen DSGVO, EU AI Act und saubere Dokumentation von Updates und Schulungen eine echte Rolle.
Was lokale KI in IoT-Systemen praktisch leistet
Ich trenne in Projekten konsequent zwischen Training und Inferenz: Das Modell wird meist zentral entwickelt, aber lokal ausgeführt. Genau dort liegt der Nutzen für IoT-Systeme. Statt Rohdaten permanent in die Cloud zu schicken, bewertet das Gerät das Signal selbst, erkennt Muster und reagiert sofort. Das kann eine Kamera sein, die Ausschuss erkennt, ein Sensor im Maschinengehäuse, der Vibrationen bewertet, oder ein Gateway, das mehrere Messpunkte zusammenführt.
Der Unterschied zur klassischen Cloud-Architektur ist nicht akademisch, sondern operativ. Wenn eine Anlage bei einer Störung innerhalb von Millisekunden oder Sekunden reagieren muss, hilft ein Cloud-Roundtrip oft nicht weiter. Wenn Daten sensibel sind, etwa bei Video, Audio oder Standortinformationen, ist lokale Verarbeitung zudem die sauberere Lösung. Und wenn die Verbindung teuer, langsam oder instabil ist, reduziert On-device-Verarbeitung den Datenverkehr spürbar. Ich würde deshalb sagen: Edge-KI ist nicht die kleine Variante von Cloud-KI, sondern eine andere Betriebslogik.
Sobald das klar ist, zeigt sich schnell, welche Anwendungsfälle im IoT zuerst profitieren.
Wo sich der Ansatz im Alltag von IoT-Systemen auszahlt
Die stärksten Use Cases sind dort zu finden, wo ein Gerät sofort entscheiden muss oder wo es schlicht unpraktisch ist, alles zentral auszuwerten. In verteilten Infrastruktur- und Telekommunikationsumgebungen gilt das besonders oft: Funkstandorte, Außenanlagen, Energieeinheiten oder entlegene Knoten profitieren von lokaler Analyse, weil Backhaul-Bandbreite nicht beliebig verfügbar ist.
| Anwendung | Warum lokal sinnvoll | Was ich daraus ableiten würde |
|---|---|---|
| Predictive Maintenance | Vibration, Temperatur und Stromaufnahme lassen sich direkt an der Maschine auswerten. | Frühwarnungen kommen schneller, und nur relevante Ereignisse werden weitergeleitet. |
| Qualitätskontrolle per Kamera | Bilder und Videos bleiben am Standort, statt permanent übertragen zu werden. | Gut für schnelle Sortierung, Fehlteil-Erkennung und visuelle Inspektion. |
| Smart Buildings und Energie | Belegung, Luftqualität oder Lastspitzen müssen oft sofort verarbeitet werden. | Die Steuerung reagiert direkter, etwa bei Lüftung, Beleuchtung oder Lastmanagement. |
| Telekommunikationsstandorte und Remote-Infrastruktur | Verbindungen sind nicht immer stabil, und jeder zusätzliche Datenstrom kostet. | Lokale Modelle helfen bei Zustandsanalyse, Anomalien und Notfallreaktionen. |
| Logistik und Lager | Scans, Bilder und Sensordaten entstehen in kurzer Taktung an vielen Punkten. | Edge-Verarbeitung reduziert Latenz und entlastet die zentrale Plattform. |
Für mich ist dabei wichtig: Nicht jeder IoT-Fall braucht KI am Rand. Einfache Schwellenwerte, klassische Regeln oder ein zentraler Dienst reichen oft völlig aus. Edge-KI lohnt sich erst dann wirklich, wenn Geschwindigkeit, Robustheit oder Datenschutz einen sichtbaren Unterschied machen. Damit die Auswahl nicht theoretisch bleibt, lohnt jetzt der Blick auf die Architektur hinter dem System.
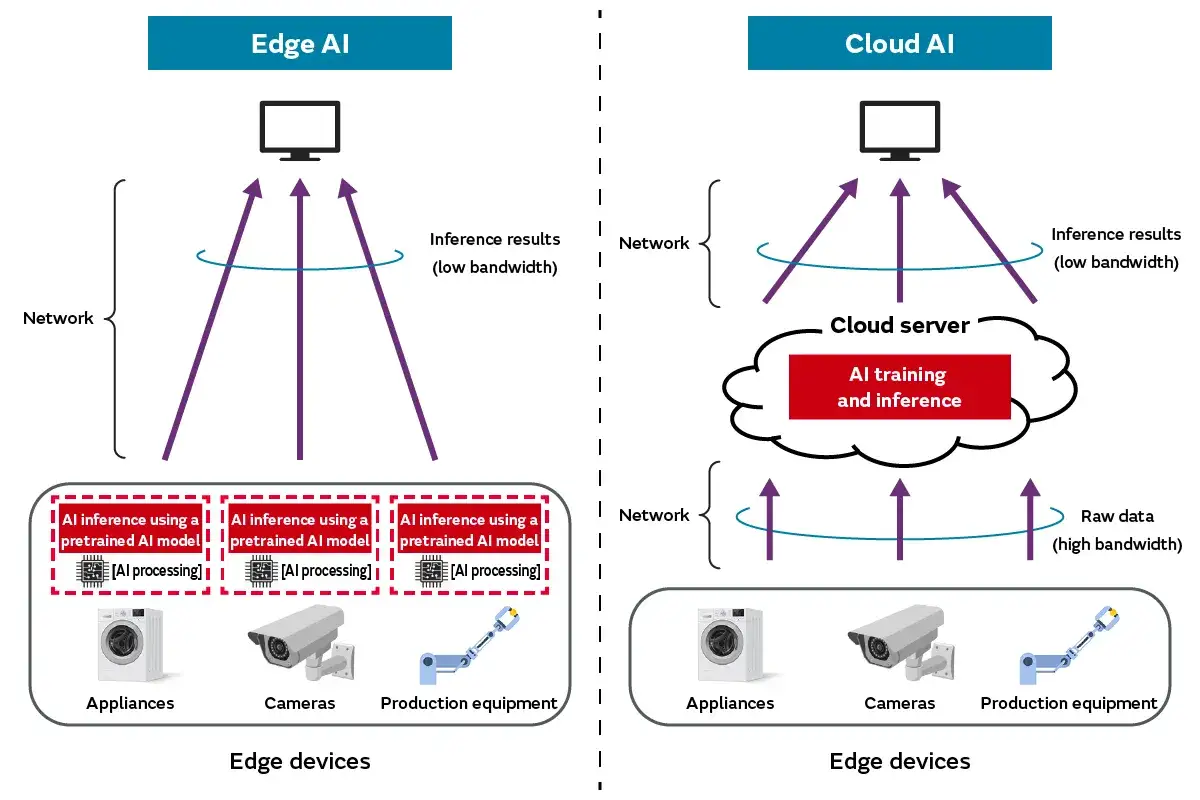
Wie die Architektur mit Sensor, Gateway und Cloud zusammenspielt
In der Praxis sehe ich drei typische Ebenen. Erstens das Endgerät selbst, also Sensor, Kamera oder Mikrocontroller. Zweitens ein lokales Gateway oder Industrie-PC, der mehrere Signale bündelt. Drittens die Cloud, die für Training, zentrale Auswertung und Flottensteuerung bleibt. Diese Aufteilung ist meist stabiler als der Versuch, alles auf ein einziges System zu drücken.
| Ebene | Typische Hardware | Aufgabe | Wann sie passt |
|---|---|---|---|
| Mikrocontroller | Sehr kleine Embedded-Boards mit wenigen Kilobytes bis wenig Speicher | Einfache Klassifikation, Wake-Events, Schwellwertlogik | Wenn Energieverbrauch extrem niedrig sein muss |
| Edge-Gateway | Industrie-PC, Router, Embedded-Computer mit CPU, GPU oder NPU | Vorverarbeitung, mehrere Modelle, Bild- oder Signalanalyse | Wenn viele Sensoren zusammenlaufen oder Daten lokal aggregiert werden sollen |
| Cloud-Plattform | Zentrale Server und Datenplattformen | Training, Langzeitanalyse, Modellverwaltung, Rollouts | Wenn Skalierung und Historie wichtiger sind als unmittelbare Reaktion |
Für sehr kleine Geräte ist der Speicher die harte Grenze. Google beschreibt für LiteRT auf Microcontrollers einen Kernlaufzeitbedarf von 16 KB auf einem Arm Cortex M3; das zeigt ziemlich gut, wie knapp die Ressourcen auf wirklich kleinen Geräten sein können. Für solche Klassen muss das Modell also nicht nur gut, sondern auch bewusst klein sein. Am anderen Ende der Skala stehen Gateways und Industrie-PCs, die deutlich mehr Raum für Bildverarbeitung, mehrere Datenströme und lokale Pufferung bieten.
Ich halte eine hybride Architektur fast immer für die vernünftigste Lösung: Das Gerät entscheidet lokal, die Cloud übernimmt das, was langfristig, schwergewichtig oder organisatorisch zentral bleiben soll. Von dort ist der nächste Schritt logisch: das Modell so zu verkleinern, dass es wirklich auf das Zielgerät passt.
Welche Modelloptimierungen auf lokale Hardware passen
Ein gutes Edge-Modell ist selten einfach ein abgespecktes Cloud-Modell. Es ist meist ein Modell, das gezielt auf Speicher, Rechenzeit und Energieverbrauch hin optimiert wurde. PyTorch und Google weisen beide darauf hin, dass gerade auf Edge-Geräten kleine Formfaktoren und begrenzte Ressourcen die Wahl der Technik stark prägen. Ich sehe in Projekten vor allem diese vier Hebel:
| Technik | Wirkung | Typischer Nachteil |
|---|---|---|
| Quantisierung | Reduziert Modellgröße und Rechenaufwand, oft auf int8-Niveau |
Kann Genauigkeit kosten, wenn die Kalibrierung schlecht ist |
| Pruning | Entfernt wenig wichtige Gewichte und spart Speicher | Bringt nur etwas, wenn das Zielgerät und der Laufzeitstack damit umgehen können |
| Clustering | Fasst ähnliche Gewichte zusammen und vereinfacht die Repräsentation | Ist nicht immer die beste Wahl für alle Modelltypen |
| Distillation | Überträgt Wissen eines großen Modells in ein kleineres Modell | Erfordert zusätzlichen Trainingsaufwand und saubere Zieldefinition |
Besonders wichtig finde ich die Quantisierung. Google beschreibt sie als Technik, die Modellgröße senken und die Latenz verbessern kann, oft mit nur geringer Genauigkeitsminderung. PyTorch betont ebenfalls, dass Quantisierung für Wearables, Embedded-Systeme und Mikrocontroller besonders relevant ist, weil dort Rechenleistung, Speicher und Akkulaufzeit knapp sind. Das ist in der Praxis oft der schnellste Weg, um ein Modell überhaupt produktionsfähig zu machen.
Gleichzeitig sollte man sich nichts vormachen: Wenn ein Modell nur mit massiver Kompression auf das Gerät passt, ist es meist das falsche Modell oder der falsche Use Case. Ich würde zuerst Eingabedaten, Sensorauflösung und Problemgrenze vereinfachen, bevor ich mich an exotische Optimierungstricks klammere. Erst danach wird die eigentliche Einführung planbar.
So setze ich ein Edge-AI-Projekt im IoT sauber auf
Wenn ich ein Projekt in diesem Bereich aufsetze, gehe ich immer in derselben Reihenfolge vor. Das spart Zeit, weil man nicht zu früh in Modellfragen abdriftet, obwohl das eigentliche Problem noch gar nicht sauber beschrieben ist.
- Use Case scharf eingrenzen. Ich definiere zuerst, welche Entscheidung das Gerät treffen soll und was als Erfolg gilt.
- Reaktionszeit und Datenfluss festlegen. Muss die Antwort sofort kommen, oder reicht eine periodische Auswertung? Wie viele Daten dürfen das Gerät verlassen?
- Hardware an die Aufgabe anpassen. Ein Mikrocontroller, ein Gateway und ein Industrie-PC sind keine austauschbaren Varianten, sondern verschiedene Klassen mit sehr unterschiedlichen Grenzen.
- Modell auf realen Daten testen. Laboraufnahmen sind nett, aber sie ersetzen nicht das Rauschen, die Temperatur und die Abweichungen des echten Betriebs.
- Monitoring für Drift und Ausfälle einrichten. Drift heißt, dass sich Daten über die Zeit verschieben und das Modell langsam schlechter wird.
- Update- und Rollback-Prozesse einplanen. MLOps am Rand bedeutet für mich, dass Firmware, Modell und Konfiguration gemeinsam versioniert und sicher ausgerollt werden.
Ein Fehler, den ich oft sehe, ist der umgekehrte Weg: Erst wird ein Modell gebaut, dann sucht man verzweifelt nach Hardware, die es irgendwie tragen kann. Das ist teuer und unzuverlässig. Deutlich besser ist es, von Anfang an die Zielgeräte, die Stromgrenzen und die Wartungslogik mitzudenken. Wer das sauber aufsetzt, reduziert spätere Überraschungen deutlich.
Was in Deutschland rechtlich und organisatorisch mitläuft
In Deutschland würde ich Edge-KI nie nur als Technikprojekt behandeln. Sobald Sensoren personenbezogene Daten, Video oder andere sensible Informationen verarbeiten, wird Datenschutz zur Designfrage. Lokale Verarbeitung hilft zwar bei der Datensparsamkeit, aber sie macht ein System nicht automatisch rechtskonform oder sicher.
Seit dem 1. August 2024 ist der EU AI Act in Kraft; die vollständige Anwendbarkeit beginnt am 2. August 2026. Für hochriskante KI-Systeme in regulierten Produkten gilt sogar eine längere Übergangsfrist bis zum 2. August 2028. Hinzu kommt die Pflicht zur KI-Kompetenz: Die Anforderungen an ausreichende AI Literacy gelten bereits seit dem 2. Februar 2025, und die Aufsicht dazu greift ab dem 3. August 2026. Für Betreiber heißt das nicht, dass jedes Team juristisch ausgebildet sein muss. Aber ich erwarte dokumentierte Schulungen, klare Zuständigkeiten und nachvollziehbare Betriebsregeln.
- Ich prüfe immer, welche Daten das Gerät wirklich verlassen und welche lokal bleiben.
- Ich halte fest, wer Modelle freigibt, Versionen prüft und Rollbacks auslösen darf.
- Ich verlange ein Minimum an Dokumentation zu Training, Betrieb und Monitoring.
- Ich plane einen sicheren Fallback, falls das Modell unsicher ist oder ausfällt.
Gerade bei IoT-Systemen ist das kein bürokratisches Beiwerk, sondern Teil der Stabilität. Wer das früh mitdenkt, baut nicht nur smarter, sondern auch belastbarer.
Woran ein Edge-IoT-Projekt am Ende wirklich gewinnt
- Die Datenqualität stimmt. Schlechte Sensordaten lassen sich lokal nicht magisch reparieren.
- Die Hardware passt zur Aufgabe. Ein zu großes Modell auf einem zu kleinen Gerät ist kein Architekturdetail, sondern ein Betriebsproblem.
- Der Betrieb ist vorbereitet. Updates, Monitoring und Rollback sind wichtiger als der erste Demo-Erfolg.
Wenn diese drei Punkte stimmen, wird lokale KI im IoT nicht zur Spielerei, sondern zu einem belastbaren Baustein für schnelle Reaktion, geringere Netzlast und mehr Robustheit. Genau dort liegt ihr eigentlicher Wert: nicht im Hype, sondern im verlässlichen Alltag von verteilten Systemen.