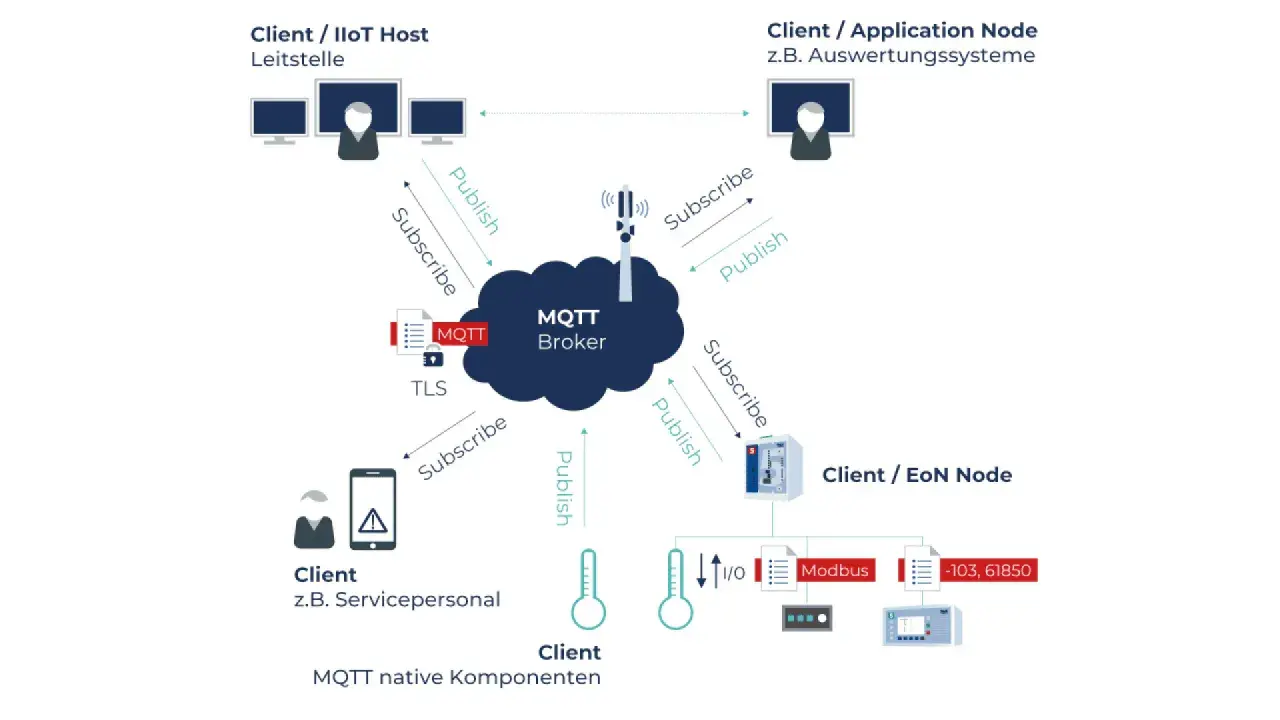
Für IoT-Systeme ist nicht nur wichtig, dass Daten ankommen, sondern auch, dass sie schnell, sparsam und für verschiedene Komponenten verständlich bleiben. MQTT übernimmt dabei den leichten Versand über den Broker, während JSON die Nutzdaten in eine Struktur bringt, die sich in Gateways, Dashboards und APIs ohne großen Übersetzungsaufwand verarbeiten lässt. Gerade bei knapper Bandbreite, wechselnder Verbindung oder vielen kleinen Sensorpaketen zahlt sich diese Kombination aus, wenn man sie sauber aufsetzt.
Die wichtigsten Punkte auf einen Blick
- MQTT transportiert, JSON beschreibt. Das Protokoll regelt Zustellung und Routing, der Payload enthält die Fachdaten.
- Topic und Payload sollten klar getrennt bleiben. Das Topic ist für den Weg der Nachricht da, nicht für den eigentlichen Inhalt.
- JSON ist stark bei Interoperabilität. Viele Systeme lesen es direkt, ohne eigenes Binärschema.
- MQTT 5 bringt nützliche Metadaten. `Content Type`, `Payload Format Indicator`, `Message Expiry` und `Topic Alias` machen Nachrichten robuster und oft kleiner.
- In schmalen Netzen zählt jedes Byte. Dann werden kurze Topics, kompakte Schlüssel und ein diszipliniertes Datenmodell besonders wichtig.
- Binäre Formate sind keine Pflicht, aber eine Option. Wenn Bandbreite oder Energie knapp werden, lohnt sich der Vergleich mit CBOR, MessagePack oder Protobuf.
Warum MQTT und JSON im IoT gut zusammenpassen
Ich setze MQTT dort ein, wo Geräte kleine Nachrichten an viele Empfänger verteilen sollen. Der Standard ist bewusst payload-agnostisch, und JSON ist ein textbasiertes Format für strukturierte Daten. Zusammen ergibt das eine Mischung, die für Geräte, Broker, Backend und Frontend gut anschlussfähig bleibt.
Der praktische Vorteil liegt nicht im Protokoll selbst, sondern in der Arbeitsweise dahinter: Sensoren senden Messwerte, ein Broker verteilt sie, und verschiedene Systeme lesen dieselbe Nachricht ohne proprietäre Umwandlung. Das ist für Telemetrie, Zustandsdaten, Alarme und einfache Steuerbefehle oft die pragmatischste Lösung. Gerade bei Infrastruktur- und Telekommunikationsprojekten in Regionen mit knapper oder wechselnder Konnektivität ist diese Reduktion von Overhead kein Luxus, sondern ein echter Betriebsfaktor. Im nächsten Schritt lohnt sich deshalb ein Blick darauf, wie eine solche Nachricht sauber aufgebaut ist.
So sieht eine saubere Nachricht mit JSON-Payload aus
Ich trenne immer drei Ebenen: Topic für das Routing, Payload für die Fachdaten und Properties für Metadaten. Wer diese Trennung sauber hält, vermeidet später viel Reibung beim Skalieren, Debuggen und Integrieren.
| Ebene | Aufgabe | Gute Praxis |
|---|---|---|
| Topic | Routing und Subscriptions | Kurz, hierarchisch, ohne Fachlogik im Namen |
| Payload | Messwerte, Status, Befehle | JSON mit stabilen Schlüsseln und klaren Einheiten |
| Properties | Zusätzliche Metadaten | `Content Type`, `Payload Format Indicator`, `Message Expiry`, `Topic Alias` |
Topic: tl/dili/gateway-07/telemetry
Payload:
{
"device_id": "gw-07",
"ts": "2026-06-10T12:15:00Z",
"temp_c": 28.4,
"humidity_rh": 71,
"battery_v": 3.78,
"status": "ok"
}Welche JSON-Strukturen sich im Feld bewähren
JSON funktioniert dann am besten, wenn die Struktur einfach genug bleibt, um in Geräten und Backend gleichermaßen stabil zu laufen. In IoT-Projekten bevorzuge ich daher eher klare, flache Objekte als tief verschachtelte Modelle, die nur der ursprüngliche Entwickler mühelos lesen kann.| Praxis | Warum das hilft | Beispiel |
|---|---|---|
| Flache Objekte | Weniger Parsing-Aufwand, weniger Interpretationsfehler | `temp_c`, `battery_v`, `status` |
| Explizite Einheiten | Niemand muss raten, ob ein Wert Celsius, Volt oder Prozent meint | `humidity_rh`, `temp_c` |
| Stabile Schlüsselnamen | Versionen bleiben kompatibler | Lieber `device_id` konsequent nutzen als abwechselnd neue Varianten einzuführen |
| Eindeutige Zeitangaben | Reihenfolge, Korrelation und Auswertung werden einfacher | ISO-8601 oder Unix-Zeitstempel in Millisekunden |
| Keine doppelten Schlüssel | Parser reagieren darauf unterschiedlich | Ein Objekt darf nicht zweimal `temp_c` enthalten |
| Vorsicht bei großen Zahlen | Sehr große IDs oder Präzisionswerte können ungenau werden | Über `9.007.199.254.740.991` lieber als String speichern |
JSON über Netzwerke gehört in UTF-8. Werte wie `NaN` oder `Infinity` gehören nicht hinein, und auf die Reihenfolge von Objektmitgliedern sollte man sich nicht verlassen. Arrays nutze ich nur dann, wenn die Reihenfolge wirklich Bedeutung hat, etwa bei Messreihen oder historischen Daten. So bleibt das Format auch dann noch zuverlässig, wenn mehrere Systeme daran andocken. Daraus folgt die nächste praktische Frage: Reicht JSON immer aus, oder ist ein binäres Format manchmal die bessere Wahl?
Wann JSON reicht und wann ein binäres Format besser ist
JSON ist oft der beste Startpunkt, aber nicht immer das Endformat. Sobald Bandbreite, Energieverbrauch oder Parser-Last messbar werden, schaue ich mir ernsthaft Alternativen an.
| Kriterium | JSON | Binäres Format |
|---|---|---|
| Lesbarkeit im Feld | Sehr hoch | Niedrig bis mittel |
| Payload-Größe | Meist größer | Meist kleiner |
| Tooling für Web und APIs | Sehr breit verfügbar | Abhängig vom Stack |
| Schema-Strenge | Eher locker | Oft strenger und klarer definiert |
| Debugging | Einfach mit Logs und Browser | Meist Spezialwerkzeug nötig |
| Typischer Einsatz | Integrationsschichten, Prototypen, Dashboards | Sehr viele Geräte, hohe Frequenzen, knappe Verbindungen |
Ich bleibe bei JSON, wenn Menschen die Daten direkt lesen oder mehrere Systeme schnell andocken sollen. Ich wechsle erst dann auf ein binäres Format wie CBOR, MessagePack oder Protobuf, wenn der praktische Nutzen messbar wird. Das ist im Alltag fast immer eine Frage von Datenvolumen, Latenz und Wartbarkeit, nicht von Ideologie. Und genau an dieser Stelle passieren in echten Projekten die meisten vermeidbaren Fehler.
Typische Fehler, die ich in IoT-Projekten immer wieder sehe
Die Probleme sind selten spektakulär, aber sie kosten Zeit. Meist entstehen sie dort, wo Transport, Datenmodell und Betrieb zu wenig sauber voneinander getrennt werden.
- Zu viele Fachdetails im Topic - Wenn das Topic selbst schon wie ein Datensatz aussieht, wird das Routing fragil und später schwer zu ändern.
- Wildcard-Zeichen in Publish-Topics - `+` und `#` gehören in Subscriptions, nicht in veröffentlichte Topic-Namen.
- Retained Messages für Live-Telemetrie - Retain ist sinnvoll für den letzten Zustand, nicht für jede einzelne Messung.
- Doppelte Schlüssel im JSON - Unterschiedliche Parser können auf denselben Payload verschieden reagieren.
- Falsche Kodierung - Wenn JSON nicht sauber in UTF-8 vorliegt, entstehen schnell schwer diagnostizierbare Fehler.
- Zu große oder ungenaue Zahlen - Präzisionswerte, IDs oder Summen sollten mit Blick auf die Zielumgebung modelliert werden, nicht nur für den schnellen Prototyp.
- Keine Ablaufzeit für temporäre Nachrichten - Befehle und Warnungen können veralten; ohne `Message Expiry` bleiben sie zu lange relevant.
- Unklare Semantik zwischen Topic und Payload - Wenn dieselbe Information an zwei Stellen steckt, entstehen Inkonsistenzen.
Wenn ich diese Punkte früh prüfe, sinkt die Zahl der Feldprobleme deutlich. Der nächste Hebel liegt dann nicht mehr im Schema, sondern in der Art, wie man das Setup für schmale Netze und reale Betriebsbedingungen auslegt.
Wie ich ein robustes Setup für schmale Netze aufbaue
In Netzen mit knapper oder schwankender Konnektivität optimiere ich zuerst die Zustellung, dann die Nutzlast und erst danach die Feinheiten. Gerade in IoT-Umgebungen mit vielen kleinen Nachrichten bringt diese Reihenfolge mehr als jede kosmetische Änderung am Datenmodell.
| Stellschraube | Empfehlung | Effekt |
|---|---|---|
QoS 0 |
Für häufige Sensordaten, wenn einzelne Werte verloren gehen dürfen | Wenig Overhead, niedrige Latenz |
QoS 1 |
Für Alarme, Konfigurationsänderungen und viele Steuerbefehle | Zustellung zuverlässiger, Duplikate möglich |
QoS 2 |
Nur wenn doppelte Zustellung wirklich problematisch wäre | Höchste Sicherheit, aber mehr Protokollaufwand |
Retained Messages |
Für den aktuellen Zustand, nicht für jede Live-Messung | Neue Abonnenten bekommen den letzten Stand sofort |
Message Expiry |
Für Alarm- und Befehlsnachrichten mit begrenzter Relevanz | Veraltete Nachrichten verschwinden automatisch |
Topic Alias |
Bei langen, oft wiederholten Topic-Namen in MQTT 5 | Kleinere PUBLISH-Pakete bei gleichbleibender Semantik |
Content Type und Payload Format Indicator
|
Wenn alle Beteiligten JSON als UTF-8 eindeutig erkennen sollen | Weniger Missverständnisse zwischen Client und Broker |
| TLS und Authentifizierung | Immer einplanen, bevor Geräte produktiv senden | Schützt Transport und Zugang zum Broker |
Der kleine, aber oft entscheidende Punkt ist hier `Topic Alias`: Wenn Topic-Namen lang sind und immer wieder auftauchen, spart das in MQTT 5 spürbar Platz. In einem Netz mit knappen Datenbudgets wirkt sich das schneller aus, als man auf den ersten Blick erwartet. Ich optimiere deshalb zuerst Nutzlast, Zustellweg und Lebensdauer der Nachricht, nicht die Ästhetik der Feldnamen. Bleibt nur noch die Frage, wie man daraus eine belastbare Arbeitsweise für echte Projekte ableitet.
Womit sich stabile MQTT-JSON-Pipelines schneller bauen lassen
Wenn ich ein neues IoT-Projekt aufsetze, definiere ich zuerst den Nachrichtenvertrag: Topic-Hierarchie, Feldnamen, Einheiten, Zeitformat und Zustandslogik. Erst danach kommen Broker, Visualisierung und Automatisierung, weil spätere Änderungen sonst unnötig teuer werden.
- Halte Topic-Namen kurz, stabil und eindeutig.
- Versioniere das Payload-Schema, statt Felder stillschweigend umzubenennen.
- Dokumentiere Einheiten direkt am Feld oder in einem klaren Datenvertrag.
- Prüfe eingehende JSON-Nachrichten sowohl am Consumer als auch an der Integrationskante.
So entsteht eine Kommunikationsschicht, die nicht nur heute funktioniert, sondern auch dann noch wartbar bleibt, wenn aus ein paar Sensoren ein echter Betrieb mit Gateways, Alarmsystemen und mehreren Standorten wird. Genau an dieser Stelle treffen effiziente Übertragung und saubere Datenstruktur aufeinander, und dort spielt die Kombination aus MQTT und JSON ihre größte Stärke aus.