
Fernaktualisierungen sind für IoT-Systeme keine Nebensache, sondern die Voraussetzung dafür, dass Geräte über Jahre sicher und wartbar bleiben. Gerade bei Telekommunikations-, Infrastruktur- und Sensornetzen wird ein remote iot software update schnell zum Betriebsrisiko, wenn Signaturen, Rollback und Monitoring nicht zusammenpassen. Ich zeige hier, wie der Prozess technisch funktioniert, welche Architektur sich bewährt und wo in der Praxis die meisten Fehler entstehen.
Die wichtigsten Punkte auf einen Blick
- Ein Update ist nur so gut wie sein Prüfprozess: Herkunft, Integrität und Zielgerät müssen vor der Installation eindeutig validiert werden.
- Rollback ist Pflicht, nicht Kür: Ohne Fallback kann ein fehlerhaftes Paket ganze Geräteflotten lahmlegen.
- Die Netzrealität bestimmt die Technik: Resumierbare Downloads, kleine Pakete und Gateways sind bei schwachen Verbindungen oft wichtiger als reine Geschwindigkeit.
- Erfolg endet nicht mit dem Download: Erst Boot, Funktionstest und Telemetrie zeigen, ob das Update wirklich sauber durchgelaufen ist.
- Sauberes Inventar spart Geld und Zeit: Wer nicht weiß, welche Version wo läuft, kann Flotten nur schlecht steuern.
Was bei einer Fernaktualisierung wirklich passiert
Ich trenne zuerst sauber zwischen Firmware und Anwendungssoftware. Firmware sitzt näher an der Hardware, steuert Bootvorgang, Funkmodul oder Sensorik und verlangt oft einen atomaren Wechsel; Anwendungssoftware läuft darüber und lässt sich häufig kleinteiliger aktualisieren. Ein brauchbarer Ablauf besteht fast immer aus fünf Stationen: Paket bauen, Herkunft prüfen, verteilen, installieren und den Zustand nach dem Neustart verifizieren.
- Updatepaket bauen - Ich erstelle nicht nur die Binärdatei, sondern auch ein Manifest mit Version, Zielhardware, Abhängigkeiten und Prüfsummen. Ohne diese Metadaten wird spätere Fehlersuche unnötig teuer.
- Herkunft und Integrität prüfen - Vor der Installation muss klar sein, dass das Paket wirklich vom richtigen Absender stammt und unterwegs nicht verändert wurde.
- Auf die Geräte bringen - Das kann direkt per Netzwerkdownload passieren oder über ein Gateway, das mehrere Endgeräte lokal versorgt. Letzteres ist bei schwachen oder teuren Verbindungen oft die bessere Wahl.
- Kontrolliert installieren - Gute Systeme schreiben nicht blind über den laufenden Zustand, sondern wechseln atomar oder in einem abgesicherten Slot. So bleibt ein Rücksprung möglich.
- Erfolg messen - Ein Update ist erst dann erfolgreich, wenn das Gerät wieder bootet, die Kernfunktionen reagieren und die Telemetrie keine neuen Fehler zeigt.
Der nächste Prüfstein ist nicht die Technik selbst, sondern die Frage, wer dieses Paket überhaupt ausrollen darf und wie sich Manipulation verhindern lässt.
Warum Sicherheit vor Geschwindigkeit kommt
NIST fordert für IoT-Geräte eine sichere, konfigurierbare Aktualisierung durch autorisierte Stellen und die Möglichkeit, die Herkunft eines Updates mit digitalen Signaturen, Checksummen oder Zertifikaten zu prüfen. Ich halte genau das für den Dreh- und Angelpunkt: Nicht das Update an sich ist das Problem, sondern ein Update, das ohne Identitätsprüfung in der Flotte landet. Wenn Updates automatisch eingespielt werden, muss die Authentisierung vor der Installation stattfinden und der Mechanismus bei Bedarf abschaltbar bleiben.
- Autorisierung - Nur definierte Personen oder Prozesse dürfen Updates einspielen, ändern oder entfernen.
- Integrität - Digitale Signaturen, Prüfsummen und Zertifikate sind die Basis, nicht ein nettes Extra.
- Konfigurierbarkeit - Ich will Updatekanäle aktivieren, pausieren oder für einzelne Gerätegruppen sperren können.
- Rückverfolgbarkeit - Version, Freigabezeitpunkt und Zielgruppe müssen nachträglich nachvollziehbar sein.
Wenn diese Leitplanken stehen, stellt sich die nächste Frage: Welche Update-Architektur hält unter realen Bedingungen wirklich durch?
Welche Architektur in der Praxis funktioniert
Ich entscheide die Architektur selten nach Geschmack, sondern nach Fehlerfolgen: Darf ein Gerät kurz ausfallen, oder darf es gar nicht ausfallen? Wie viel Speicher steht zur Verfügung? Muss das System zurückspringen können, wenn der neue Stand nicht bootet? Auf diese drei Fragen liefern die üblichen Muster sehr unterschiedliche Antworten.
| Ansatz | Vorteil | Grenze | Typisch sinnvoll |
|---|---|---|---|
| Vollimage | Einfach zu validieren, klarer Zustandswechsel | Hoher Bandbreiten- und Speicherbedarf | Wenn Stabilität wichtiger ist als Paketgröße |
| Delta-Update | Es werden nur Änderungen übertragen | Abhängig von einer sauberen Basisversion | Bei teuren oder langsamen Verbindungen |
| A/B-Slots | Rollback auf die alte Version bleibt möglich | Benötigt meist mehr Speicher | Bei Geräten, die nicht ausfallen dürfen |
| App- oder Container-Update | Trennt Fachlogik sauber vom Systemimage | Hilft nicht gegen Probleme im Kernsystem | Bei Edge-Gateways und Linux-Geräten |
| Gateway-verteiltes Update | Ein zentraler Punkt speist viele Endgeräte | Das Gateway wird selbst zum kritischen Baustein | Bei entlegenen Standorten oder Mesh-Netzen |
Für kritische Geräte bevorzuge ich eine Fallback-Strategie wie A/B oder einen gleichwertigen zweiten Slot; bei knappen Ressourcen gewinnen Delta-Updates und gatewaygestützte Verteilung. Das sauberste Muster ist immer das, das zu Speicher, Netz und Ausfalltoleranz passt, nicht das mit dem längsten Marketingnamen.
Wie man daraus einen Rollout macht, entscheidet oft über den Unterschied zwischen Wartung und Störung.
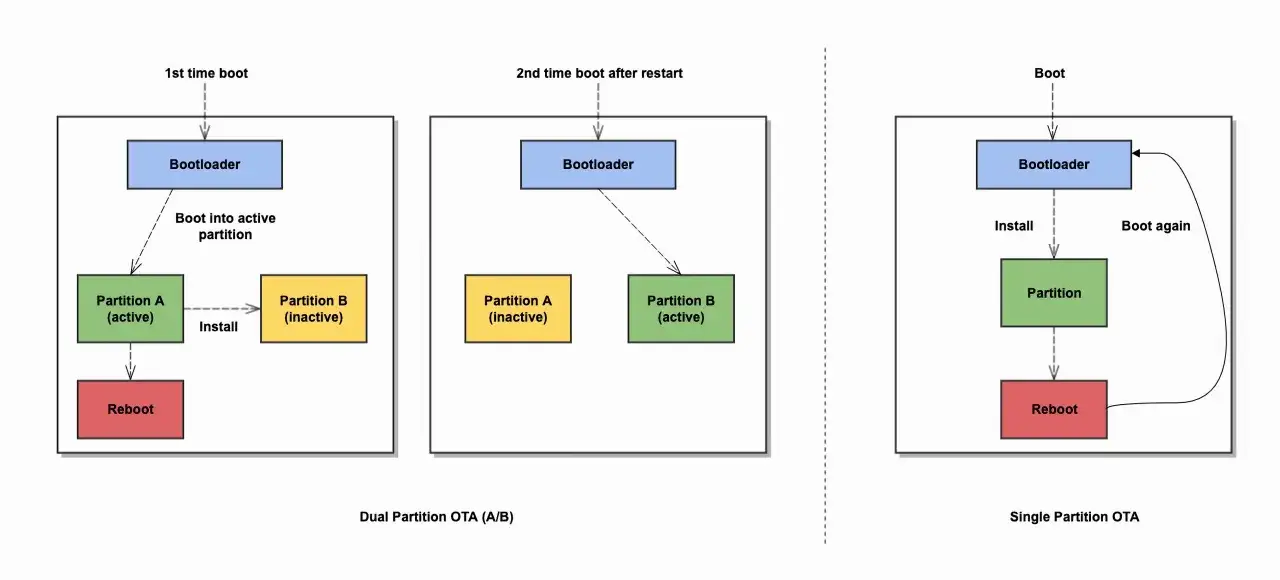
So setze ich einen sauberen Rollout auf
ETSI beschreibt OTA-Updates als zentral für die langfristige Sicherheit vernetzter Geräte. In der Praxis heißt das für mich: nicht sofort die ganze Flotte anfassen, sondern die Verteilung in Wellen planen und jeden Schritt beweisen.
- Inventar aufnehmen - Ich brauche vor dem Start eine belastbare Liste aller Gerätemodelle, Hardware-Revisionen und installierten Versionen. Ohne das bleibt jede Freigabe ein Ratespiel.
- Labor und Pilotgruppe testen - Ich prüfe zuerst an repräsentativen Geräten, nicht nur am Lieblingsgerät im Testregal. Gerade schwache Funkverbindungen oder volle Speichermedien zeigen Probleme früh.
- Update signieren und freigeben - Die Freigabe gehört in eine nachvollziehbare Pipeline, in der Schlüssel, Version und Zielgruppe klar dokumentiert sind.
- Gestaffelt ausrollen - Ich starte mit einer kleinen Kohorte, beobachte Verhalten und gehe erst dann in die nächste Welle. Das senkt die Zahl gleichzeitig betroffener Geräte massiv.
- Während des Rollouts messen - Installationsrate, Boot-Erfolg, Reaktionszeiten und Fehlermeldungen gehören live beobachtet. Ein Paket, das ankommt, ist noch kein erfolgreiches Update.
- Rollback-Regel festlegen - Ich definiere vorab, wann zurückgerollt wird, wer freigibt und wie lange auf einen sauberen Boot gewartet wird.
- Nacharbeit dokumentieren - Fehlerbilder, Nebenwirkungen und Abhängigkeiten schreibe ich direkt in die Betriebsdokumentation. Das spart späteren Teams viel Zeit.
Gerade bei Außenstandorten, die nur über Mobilfunk oder schmale Leitungen angebunden sind, ist diese Staffelung mehr als Vorsicht; sie ist die einzige realistische Betriebsform. Ob das Paket klein oder groß ist, wird danach zum eigentlichen Thema.
Welche Netze und Geräte den größten Unterschied machen
Bei entlegenen Sensoren, Gateways oder Telekommunikationsknoten sehe ich drei Probleme immer wieder: Verbindungen brechen ab, Speicher ist knapp und Energie muss geschont werden. Deshalb setze ich bei solchen Umgebungen lieber auf resumierbare Downloads, komprimierte Pakete und lokale Zwischenspeicher am Gateway als auf einen einzigen großen Download direkt auf jedem Endgerät.
- Resumierbare Downloads - Wenn die Verbindung abreißt, muss das Paket nicht bei null beginnen. Das ist bei instabilen Netzen oft der entscheidende Unterschied.
- Delta-Updates nur mit sauberer Basisversion - Kleine Patches sind effizient, aber nur dann, wenn die Ausgangsversion genau bekannt ist. Sonst wird ein Vollpaket oft robuster.
- Gateway als Verteiler - Ein zentraler Standort lädt das Paket einmal herunter und gibt es lokal an viele Geräte weiter. Das reduziert Backhaul-Last und Fehlerquellen.
- Lastarme Zeitfenster - Ich plane Updates möglichst dann, wenn Funkzellen, Leitungen oder Geräte ohnehin weniger belastet sind.
- Post-Update-Telemetrie - Ich prüfe nicht nur, ob das Paket installiert wurde, sondern ob das Gerät danach wieder sauber arbeitet und erreichbar bleibt.
Wenn diese Bedingungen ignoriert werden, entsteht fast immer derselbe Effekt: Das Update ist technisch „durch“, aber die Anlage arbeitet nicht zuverlässig weiter.
Die häufigsten Fehler, die ich in IoT-Flotten sehe
Die meisten Ausfälle nach Fernaktualisierungen kommen nicht von der Signaturprüfung, sondern von organisatorischen Lücken. Ich sehe vor allem sechs Fehlerbilder, die sich erstaunlich hartnäckig wiederholen.
- Kein vollständiges Versionsinventar - Niemand weiß exakt, welches Gerät auf welchem Stand läuft, und genau dann wird Fehlersuche unnötig teuer.
- Rollback nie getestet - Der Rückweg existiert nur auf dem Papier. In der Krise ist das kein Rückweg, sondern ein Wunsch.
- Pilotphase übersprungen - Die ganze Flotte wird zum ersten echten Testfeld, und das ist fast immer zu früh.
- Erfolg falsch definiert - Ein abgeschlossener Download wird mit einem funktionierenden Gerät verwechselt.
- Abhängigkeiten übersehen - Firmware, App, Konfiguration und Bibliotheken passen nicht zusammen, obwohl jedes Einzelteil für sich sauber wirkt.
- Zu wenig Kommunikation - Betrieb, Service und Kunden erfahren erst im Fehlerfall von der Umstellung.
Die Gegenprobe ist einfach: Wer eine Update-Strategie kaufen oder bauen will, sollte nach harten Belegen fragen statt nach Versprechen.
Woran ich eine gute Update-Strategie erkenne
Ich bewerte eine Update-Strategie an ein paar klaren Punkten. Sobald einer davon fehlt, wird der Betrieb später unnötig teuer.
- Signierte Pakete - Ohne geprüfte Herkunft kein produktiver Rollout.
- Rollback oder Fallback - Wenn etwas schiefgeht, muss das Gerät weiter nutzbar bleiben.
- Saubere Inventarisierung - Versionen, Hardwarestände und Verbindungen müssen sichtbar sein.
- Stufenweiser Rollout - Kleine Wellen schlagen Fehler früh auf, bevor sie die ganze Flotte treffen.
- Post-Update-Checks - Erfolg zählt erst, wenn der Dienst wieder stabil läuft.
- Dokumentierte Betriebsregeln - Wer darf ausrollen, pausieren oder zurückrollen, muss vorab feststehen.
Wenn ein Anbieter diese Punkte nicht klar beantworten kann, ist die Technik meist weniger ausgereift, als das Präsentationsmaterial vermuten lässt. Genau deshalb lohnt sich der letzte Blick auf die Teile, die man vor dem ersten Feldrollout absichert.
Was ich für verteilte Standorte zuerst absichere
Wenn ich ein IoT-System für Außenstandorte, Netzknoten oder andere verteilte Anlagen vorbereite, sichere ich zuerst drei Dinge: das vollständige Geräteinventar, die kryptografische Update-Kette und einen getesteten Fallback. Alles andere ist wichtig, aber ohne diese Basis wird jeder Rollout zum Glücksspiel.
- Inventar - Ich will jederzeit sehen, welches Gerät welche Version und welche Hardware-Revision hat.
- Vertrauenskette - Update, Manifest und Schlüssel müssen zusammenpassen und nachvollziehbar bleiben.
- Fallback - Ein zweiter lauffähiger Zustand oder ein geprüfter Rücksprung ist Pflicht, kein Luxus.
Für Betreiber in Deutschland und in ähnlich verteilten Netzen ist das die pragmatischste Form von Resilienz: weniger Vor-Ort-Einsätze, weniger ungeplante Ausfälle und eine Flotte, die auch dann handhabbar bleibt, wenn die Verbindung schwankt oder ein Standort weit entfernt liegt.