Verlässliche IoT-Systeme scheitern selten an einem einzelnen Sensor, sondern an der Verwaltung dahinter. Im Kern geht es bei iot management um Registrierung, Überwachung, Konfiguration, Aktualisierung und das saubere Außerbetriebnehmen vernetzter Geräte über ihren gesamten Lebenszyklus. Ich gehe hier praxisnah durch die Bausteine, die im Betrieb wirklich zählen, und zeige, worauf ich bei verteilten Umgebungen mit schwankender Konnektivität achte.
Die wichtigsten Punkte für eine belastbare Geräteverwaltung
- Geräteverwaltung endet nicht beim Onboarding, sondern umfasst Inventar, Telemetrie, Policy-Steuerung, Updates und Stilllegung.
- Device Twins oder digitale Zwillinge trennen gewünschten Zustand von gemeldetem Zustand und machen Flotten steuerbar.
- OTA-Updates sollten in Wellen laufen, mit klarer Rückfallstrategie und sichtbarer Erfolgsquote.
- Sicherheit beginnt bei eindeutiger Identität, Zertifikaten, Rechtevergabe und signierter Firmware.
- Edge- und Hybrid-Modelle sind oft robuster als reine Cloud-Ansätze, wenn Verbindungen nicht dauerhaft stabil sind.
Was Geräteverwaltung im IoT tatsächlich leisten muss
Wenn ich ein IoT-Projekt bewerte, frage ich nicht zuerst nach dem Dashboard, sondern nach dem Lebenszyklus der Geräte. Ein System ist nur dann beherrschbar, wenn ich jedes Gerät eindeutig identifizieren, konfigurieren, beobachten und bei Bedarf auch wieder sauber zurückziehen kann. Genau an dieser Stelle wird aus einer Sammlung einzelner Geräte eine echte Flotte.
Praktisch heißt das: Ein Sensor, ein Gateway oder ein Controller muss nicht nur Daten senden, sondern auch Metadaten tragen, zum Beispiel Standort, Rolle, Firmware-Version, Verantwortlichen und Verbindungsstatus. In Infrastrukturprojekten ist das besonders wichtig, weil Geräte oft an Masten, in Technikschränken, an Pumpstationen oder an schwer zugänglichen Außenstellen hängen. Ohne saubere Verwaltung wird jeder Fehler schnell zu einem Vor-Ort-Einsatz.
Ich trenne in der Praxis immer zwischen sichtbarem Zustand und gewünschtem Zustand. Der sichtbare Zustand ist das, was ein Gerät meldet: online, offline, Batterie schwach, Temperatur zu hoch, Firmware alt. Der gewünschte Zustand beschreibt, wie das Gerät eigentlich arbeiten soll. Diese Trennung ist die Grundlage für verlässliche Steuerung und später auch für Automatisierung. Darauf baut die Plattformarchitektur auf.
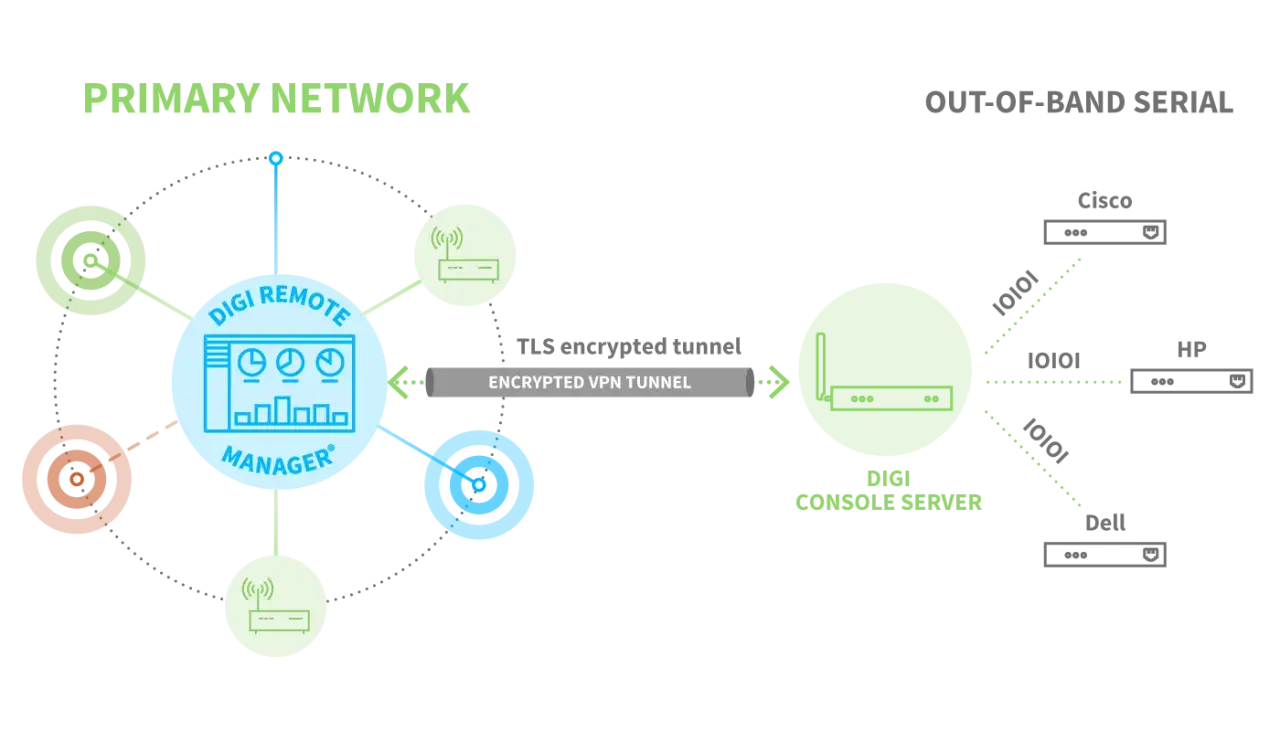
Die Bausteine, die jede Plattform braucht
| Baustein | Wofür er da ist | Woran ich die Qualität erkenne |
|---|---|---|
| Geräteregister | Hält fest, welche Geräte existieren, wo sie stehen und wem sie zugeordnet sind. | Saubere Metadaten, eindeutige IDs, Such- und Filterfunktionen. |
| Telemetry | Liefern Messwerte, Status und Ereignisse aus dem Feld. | Klare Sendeintervalle, wenig Datenverlust, sinnvolle Grenzwerte. |
| Device Twin | Spiegelt Konfiguration und gemeldeten Zustand zwischen Gerät und Plattform. | Konfigurationsabweichungen sind sichtbar und können gezielt korrigiert werden. |
| Remote Commands | Erlaubt Neustart, Parametrierung oder andere Fernaktionen. | Bestätigungen, Timeouts und Protokollierung sind vorhanden. |
| Update-Orchestrierung | Rollt Firmware und Software kontrolliert aus. | Stufenweiser Rollout, Rollback, Versionskontrolle, Erfolgsmessung. |
| Alarmierung | Informiert über Ausfälle, Anomalien oder Sicherheitsprobleme. | Wenige, aber relevante Alarme statt Alarmflut. |
| Audit-Log | Dokumentiert, wer wann welche Änderung vorgenommen hat. | Nachvollziehbarkeit für Betrieb, Sicherheit und Compliance. |
Die meisten Teams unterschätzen, dass diese Bausteine zusammenhängen. Ein starkes Update-Modul ohne Inventar bleibt blind, ein gutes Inventar ohne Telemetrie bleibt statisch. Erst die Kombination macht aus vielen Geräten eine steuerbare Flotte. Genau deshalb plane ich den Betrieb in klaren Schritten statt nach Bauchgefühl.
So organisiere ich den Betrieb vom Onboarding bis zur Stilllegung
Ein belastbarer Prozess beginnt vor dem ersten Gerät im Feld. Ich lege zuerst fest, welche Gerätetypen es gibt, welche Verbindungsarten sie nutzen, welche Standorte sie bedienen und welche Daten sie wirklich liefern müssen. Danach kommt das Onboarding. Das bedeutet in der Praxis: eindeutige Identität vergeben, Zertifikate oder Schlüssel hinterlegen, Gerätegruppe zuweisen und die ersten Basisparameter setzen.
- Inventar aufbauen - Jedes Gerät bekommt eine eindeutige Identität, eine Rolle und einen Ort. Ohne diese drei Angaben entstehen später Lücken im Betrieb.
- Geräte sicher provisionieren - Ich vermeide gemeinsame Zugangsdaten. Jedes Gerät sollte individuell authentifiziert werden, idealerweise mit Zertifikaten oder vergleichbar starken Mechanismen.
- In sinnvolle Gruppen sortieren - Statt alles einzeln zu behandeln, gruppiere ich nach Region, Funktion, Kritikalität oder Firmware-Stand. Das spart Zeit bei Änderungen.
- Telemetrie und Alarme definieren - Nicht jeder Messwert muss im Sekundentakt kommen. Für viele Betriebsfälle reichen Intervalle zwischen 30 Sekunden und 15 Minuten, solange die Eskalationslogik sauber ist.
- Updates in Wellen ausrollen - Ich starte oft mit 1 bis 5 Prozent einer Flotte, prüfe Stabilität und erhöhe dann schrittweise. Bei kritischen Geräten ist das langsamer, aber deutlich sicherer.
- Stilllegung dokumentieren - Wenn ein Gerät ausgetauscht wird, lösche ich nicht nur den Eintrag. Ich ziehe Zertifikate zurück, archiviere Konfigurationen und prüfe, ob noch Referenzen in Berichten oder Regeln existieren.
Gerade bei weit verteilten Anlagen lohnt sich diese Disziplin. Wer den Lebenszyklus sauber führt, muss bei Störungen nicht improvisieren. Und genau an der Stelle wird Sicherheit zum nächsten großen Thema.
Sicherheit und Updates, bevor das System teuer wird
IoT-Sicherheit beginnt nicht bei der Firewall, sondern bei der Identität des Geräts. Wenn ich ein System absichere, denke ich in Schichten: Gerät, Verbindung, Plattform und Betrieb. Ein gutes Passwortkonzept allein reicht nicht. Wichtiger sind eindeutige Geräteidentitäten, verschlüsselte Kommunikation, getrennte Rollen für Betrieb und Entwicklung sowie eine Firmware, deren Herkunft überprüfbar ist.
- Ein Gerät, eine Identität - Gemeinsame Zugänge sind ein Problem, weil sie im Fehlerfall nicht sauber entzogen werden können.
- Verschlüsselung und Signaturen - Kommunikation und Firmware sollten geprüft werden, bevor Daten oder Updates akzeptiert werden.
- Rechte mit Maß - Support, Betreiber und Hersteller brauchen nicht dieselben Zugriffsrechte.
- Staged Rollouts - Ein Update wird erst dann breit ausgerollt, wenn es in einer kleinen Gruppe stabil gelaufen ist.
- Rollback einplanen - Wer im Ernstfall nicht zurück kann, hat keinen robusten Update-Prozess.
- Anomalien mitdenken - Ungewöhnliche Verbindungsversuche, neue Ports oder sprunghafte Datenmuster sind oft frühe Warnsignale.
Ich halte einen Punkt für besonders wichtig: Ein Update gilt nicht als erfolgreich, nur weil das Paket übertragen wurde. Erfolg heißt erst, dass das Gerät nach dem Neustart wieder sauber meldet, die neue Version aktiv ist und der Betriebszustand stabil bleibt. Genau deshalb gehört Monitoring eng an das Update-Design.
Welches Plattformmodell zu welchem Einsatz passt
Es gibt nicht das eine richtige Modell. Für mich entscheidet vor allem, wie zuverlässig die Verbindung ist, wie kritisch die Latenz wird und wie nah am Gerät Entscheidungen fallen müssen. Wer das ignoriert, kauft schnell eine Plattform, die auf dem Papier stark aussieht, im Feld aber zu viel von einer perfekten Verbindung erwartet.
| Modell | Stärken | Grenzen | Geeignet für |
|---|---|---|---|
| Cloud-zentriert | Zentrale Sicht, gute Skalierung, starke Analysefunktionen. | Abhängig von stabiler Verbindung und gutem Backhaul. | Standorte mit verlässlicher Konnektivität und vielen Datenquellen. |
| Hybrid | Lokale Autonomie, Pufferung, späterer Abgleich mit der Cloud. | Mehr Architekturaufwand und mehr bewegliche Teile. | Verteilte Anlagen, Außenstandorte, Infrastruktur mit gelegentlichen Ausfällen. |
| Edge-first | Sehr geringe Latenz, lokale Entscheidungsfähigkeit, hohe Robustheit offline. | Mehr Anforderungen an Gateways, Wartung und lokale Logik. | Kritische Steuerungen, abgelegene Standorte, restriktive Bandbreite. |
Bei Infrastruktur- und Telekommunikationsprojekten landet man oft bei einem Hybridmodell. Das ist kein Kompromiss aus Bequemlichkeit, sondern häufig die vernünftigste Antwort auf schwankende Netzqualität, begrenzte Wartungsfenster und Geräte, die vor Ort weiterarbeiten müssen, selbst wenn die Cloud kurz nicht erreichbar ist. Darum lohnt es sich, auch die typischen Fehler offen anzuschauen.
Typische Fehler, die ich in Projekten immer wieder sehe
- Kein sauberes Inventar - Dann weiß am Ende niemand, welche Version wo läuft oder welches Gerät überhaupt betroffen ist.
- Updates für die ganze Flotte auf einmal - Das spart kurzfristig Zeit, erhöht aber das Risiko eines flächigen Ausfalls massiv.
- Zu viele oder zu wenige Alarme - Beides ist schlecht. Alarmflut stumpft Teams ab, zu wenig Alarm führt zu späten Reaktionen.
- Konfiguration und Firmware vermischen - Wenn beides ohne Trennung geändert wird, wird Fehlersuche unnötig teuer.
- Offline-Fälle nicht mitdenken - Wer nur den Normalbetrieb modelliert, fällt bei Verbindungsproblemen in manuelle Sonderprozesse zurück.
- Sicherheit erst am Ende prüfen - Dann werden strukturelle Fehler oft nur noch mit Workarounds kaschiert.
Der teuerste Fehler ist meistens nicht die fehlende Funktion, sondern die fehlende Betriebsroutine. Ein gutes System muss nicht perfekt sein, aber es muss verlässlich reagieren können, wenn etwas schiefgeht. Genau deshalb schließe ich mit den Prioritäten, die aus meiner Sicht am stärksten auf Stabilität einzahlen.
Was ich für stabile IoT-Systeme priorisiere
Wenn ich ein System auf Alltagstauglichkeit prüfe, setze ich vier Prioritäten ganz nach oben: Identität, Sichtbarkeit, kontrollierte Updates und lokale Handlungsfähigkeit. Diese vier Punkte entscheiden häufiger über den Erfolg als die Frage, ob eine Plattform besonders viele Funktionen in der Oberfläche zeigt. Für entlegene Funkstandorte, Energieanlagen oder verteilte Messnetze ist das oft der Unterschied zwischen laufendem Betrieb und dauerndem Notfallmodus.
Mein pragmatischer Rat ist deshalb simpel: klein anfangen, aber sauber. Eine Gerätegruppe, ein Updatepfad, ein Alarmset, ein getesteter Rollback und ein klarer Verantwortlicher bringen mehr als ein überladenes Projekt mit unklaren Zuständigkeiten. Wer diese Basis beherrscht, kann später Analytics, Automatisierung und weitere IoT-Funktionen darauf aufbauen, ohne das Fundament jedes Mal neu zu riskieren.