Ein gutes IoT-Dashboard bündelt Telemetrie, Gerätestatus und Alarmmeldungen so, dass ein Betriebsteam nicht mehrere Systeme öffnen muss, um ein Problem zu verstehen. Gerade bei verteilten Sensoren, Gateways und schwankender Konnektivität entscheidet die Oberfläche darüber, ob aus Daten wirklich handlungsfähiger Betrieb wird. Ich zeige hier, welche Kennzahlen zählen, wie ich die Ansicht strukturiere und woran ein belastbares Setup in der Praxis scheitert.
Die wichtigsten Punkte auf einen Blick
- Ein IoT-Dashboard ist vor allem ein Arbeitswerkzeug für Betrieb, Wartung und schnelle Entscheidungen, nicht nur eine hübsche Datenwand.
- Wichtige Kennzahlen sind Verbindungsstatus, Datenalter, Signalqualität, Batteriestand, Fehlerraten und Firmware-Stand.
- Ein brauchbares Dashboard zeigt Live-Daten, Trends, Schwellenwerte und Drill-downs pro Gerät, Standort und Flotte.
- Für unterschiedliche Rollen braucht es unterschiedliche Ansichten, sonst wird die Oberfläche zu voll und unklar.
- In Netzen mit schwacher Verbindung sind Pufferung, Priorisierung und klare Alarmregeln entscheidend.
- Eine gute Plattform spart Zeit nur dann, wenn sie zum Datenmodell und zum Betriebsmodell passt.
Was ein iot dashboard in der Praxis leisten muss
Ich bewerte eine solche Oberfläche immer an drei Fragen: Was ist betroffen, wie kritisch ist es, und was ist der nächste sinnvolle Schritt? Wenn ich das in wenigen Sekunden sehe, arbeitet das Dashboard. Wenn ich erst filtern, exportieren und durch mehrere Menüs klicken muss, verliere ich Zeit und damit im Zweifel auch Verfügbarkeit.
Für den Alltag ist wichtig, dass das Dashboard nicht nur misst, sondern auch ordnet. Ein Techniker braucht Seriennummer, letzter Kontakt, Signalqualität, Batteriestand und die letzte Fehlermeldung. Ein Betriebsverantwortlicher braucht eher Verfügbarkeit nach Standort, Störungstrends, Eskalationen und den Status offener Tickets. Ich denke deshalb in Rollen, nicht in einzelnen Diagrammen.
Ein nützliches Dashboard beantwortet außerdem innerhalb kurzer Zeit vier praktische Fragen: Welche Geräte sind betroffen? Seit wann? Wie stark ist der Einfluss auf den Betrieb? Und was muss ich jetzt tun? Genau an diesem Punkt trennt sich ein echtes Steuerungswerkzeug von einer bloßen Visualisierung. Von hier aus ist der nächste Schritt logisch: Welche Kennzahlen gehören überhaupt auf die Oberfläche?
Welche Kennzahlen und Ansichten den Unterschied machen
Nicht jede verfügbare Messgröße verdient einen Platz ganz oben. Ich halte die Oberfläche bewusst schlank und priorisiere die Werte, die Ausfälle früh sichtbar machen oder eine Entscheidung auslösen. Als Faustregel gilt: Für Live-Betrieb aktualisiere ich in Sekunden, für Zustands- und Umweltmessungen oft in Minuten. Entscheidend ist nicht maximale Geschwindigkeit, sondern die passende Taktung pro Anwendungsfall.| Kennzahl | Warum sie wichtig ist | Praktische Darstellung | Typischer Fehler |
|---|---|---|---|
| Verbindungsstatus und letzter Kontakt | Zeigt sofort, ob ein Gerät online, offline oder nur veraltet ist | Ampel, Zeitstempel und Alarm bei Ausfall über definierter Dauer | Nur „online/offline“ anzeigen, ohne den letzten Kontakt zu zeigen |
| Datenalter und Latenz | Verhindert, dass alte Werte wie aktuelle Daten wirken | „Vor 32 Sekunden empfangen“, plus Verzögerungstrend | Historische Werte als Live-Zustand interpretieren |
| Signalqualität und Paketverlust | Deckt Funkprobleme, schlechte Backhaul-Strecken oder Gateway-Störungen auf | RSSI, SNR, Reconnect-Zähler und Trendpfeile | Nur das Gerät betrachten, nicht die Übertragungsstrecke |
| Batteriestand und Energieverbrauch | Hilft, Ausfälle vor Ort zu vermeiden | Prozentwert plus Entladetrend und geschätzte Restlaufzeit | Nur einen Prozentwert ohne Verlauf anzeigen |
| Fehler- und Alarmhäufigkeit | Zeigt Muster, die auf größere Probleme hindeuten | Events pro Tag, Fehlercodes und Eskalationsstufe | Einzelalarme ohne Bündelung oder Priorität |
| Firmware- und Konfigurationsstand | Wichtig für Rollouts, Sicherheit und Compliance | Version pro Gerätegruppe, Fortschritt und Abweichungen | Geräte mit unterschiedlichen Versionen unbemerkt mischen |
Für Live-Ansichten setze ich auf wenige, dafür klare Charts: Status nach Standort, Geräte nach Gruppe, Trend der letzten Stunden und eine Alarmleiste oben. Für Management-Ansichten funktionieren eher Tages- und Wochenverläufe, SLA-Kennzahlen und Standortvergleiche. So entsteht ein Bild, das nicht überlädt, sondern erklärt. Daraus ergibt sich als Nächstes die Frage, welche Art von Oberfläche überhaupt sinnvoll ist.
Welche Dashboard-Arten ich für IoT-Systeme trenne
Ein einziges Dashboard für alle Aufgaben klingt bequem, ist in der Praxis aber selten gut. Unterschiedliche Rollen brauchen unterschiedliche Tiefe, Aktualität und Sprache. Ich trenne deshalb mindestens drei Ansichten, die sich denselben Datenpool teilen, aber anders verdichten.
| Typ | Ziel | Typische Inhalte | Wann ich ihn wähle |
|---|---|---|---|
| Live-Betriebsdashboard | Störungen sofort erkennen und reagieren | Verbindungsstatus, Alarme, letzte Messwerte, Hotspots | Wenn Ausfälle schnell auffallen müssen und das Team aktiv eingreifen soll |
| Fleet-Dashboard | Den Gesamtzustand der Geräteflotte verstehen | Geräteanzahl, Versionen, Standorte, Compliance, Gruppenvergleich | Wenn mehrere Teams, Regionen oder Rollouts parallel laufen |
| Analyse-Dashboard | Trends, Muster und Kapazitäten auswerten | Langzeitverläufe, Ausreißer, saisonale Muster, Prognosen | Wenn Entscheidungen über Wartung, Ausbau oder Optimierung anstehen |
Ich sehe oft, dass Teams mit einem einzigen Mix aus Live-Daten und historischen Berichten starten. Das ist verständlich, führt aber schnell zu unklaren Prioritäten. Besser ist es, die Ansichten sauber zu trennen und nur über klickbare Tiefenansichten zu verbinden. Dann bleibt die Oberfläche schnell genug für den Alltag und trotzdem aussagekräftig für die Analyse. Wie ich so etwas aufbaue, ist der nächste praktische Schritt.
So baue ich die Oberfläche Schritt für Schritt auf
Mit einer fertigen Plattform komme ich oft in wenigen Tagen zu einem ersten brauchbaren Stand. Eine maßgeschneiderte Web-App braucht eher Wochen bis Monate. Der Unterschied liegt nicht nur in der Technik, sondern vor allem im Umfang der Entscheidungen: Welche Rollen gibt es? Welche Alarme sind kritisch? Welche Daten dürfen sichtbar sein?
- Ich definiere zuerst den Hauptzweck. Geht es um Betrieb, Wartung, Reporting oder Rollout-Steuerung? Ohne diese Antwort wird das Dashboard schnell beliebig.
- Ich standardisiere Geräte- und Standortdaten. Tags, Namenskonventionen und Gruppen müssen sauber sein, sonst lassen sich keine stabilen Filter und Vergleiche bauen.
- Ich priorisiere die Widgets. Ganz oben stehen Status, Alarme und die wichtigsten Kennzahlen. Tiefere Analysen gehören nach unten oder in Unteransichten.
- Ich definiere Schwellenwerte mit Kontext. Eine Warnung für einen Kühlcontainer ist etwas anderes als eine Warnung für einen Umweltsensor. Schwellwerte sind immer an den Anwendungsfall gebunden.
- Ich baue Drill-downs statt Informationsmüll. Die Hauptansicht bleibt kompakt, Detailansichten liefern Gerätehistorie, Ereignisse und Rohdaten.
- Ich teste echte Störungen. Ich simuliere Verbindungsabbrüche, verzögerte Daten, leere Batterien und falsche Messwerte, bevor ich die Oberfläche produktiv nutze.
Dieser Ablauf verhindert, dass das Projekt an der Oberfläche hängen bleibt. Er zwingt dazu, technische und operative Fragen zusammenzudenken. Damit landet man automatisch bei der Architektur dahinter, also bei der Frage, wie Daten überhaupt ins Dashboard gelangen.
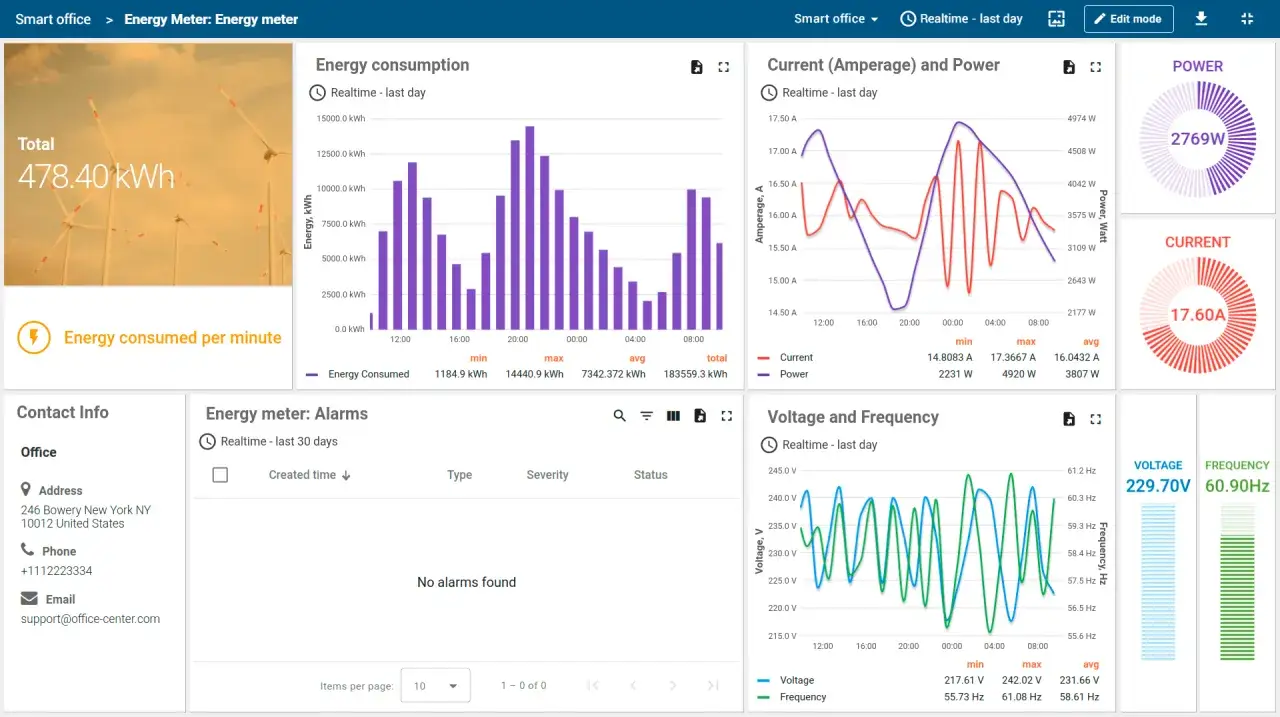
Wie die Daten vom Gerät ins Dashboard kommen
Ein Dashboard ist nur die sichtbare Schicht. Darunter liegt ein Datenfluss aus Gerät, Übertragung, Verarbeitung, Speicherung und Visualisierung. Ich trenne diese Schichten bewusst, weil Fehler oft an der Schnittstelle entstehen und nicht am eigentlichen Sensor. AWS betont bei IoT-Monitoring ausdrücklich, dass man die gesamte Kette aus Erfassung, Logging und Fehlersuche im Blick behalten sollte.
| Schicht | Aufgabe | Worauf ich achte |
|---|---|---|
| Gerät oder Sensor | Messwerte erzeugen | Messfrequenz, Energieverbrauch, lokale Uhrzeit, Fehlercodes |
| Gateway oder Edge | Daten sammeln, puffern und teilweise vorverarbeiten | Edge bedeutet Verarbeitung nahe am Gerät, nicht erst in der Cloud |
| Transport | Daten sicher übertragen | MQTT ist ein leichtgewichtiges Publish/Subscribe-Protokoll für Telemetrie; bei anderen Fällen kommen auch HTTP oder proprietäre Funkwege vor |
| Verarbeitung | Normalisieren, filtern, Regeln auslösen | Rohdaten, bereinigte Daten und Alarme sauber trennen |
| Speicherung | Historie, Audit und Analyse ermöglichen | Zeitreihen, Aufbewahrungsfristen und Zugriffskontrolle |
| Visualisierung | Den Betrieb lesbar machen | Charts, Karten, Tabellen, Alarmflächen und Tiefenansichten |
Wichtig ist dabei ein realistisches Erwartungsmanagement: Wenn ein Gerät nur alle zehn Minuten sendet, darf die Oberfläche nicht aussehen, als würde sie jede Sekunde aktualisiert. Sonst entsteht ein falsches Sicherheitsgefühl. Ich prüfe deshalb immer, ob die angezeigte Frische auch zur tatsächlichen Datenfrequenz passt. Genau an dieser Stelle passieren die meisten Fehler in der Praxis.
Typische Fehler, die aus guten Daten schlechte Entscheidungen machen
Ich sehe immer wieder dieselben Muster, auch in technisch sauberen Projekten. Das Problem ist selten die Erfassung, sondern die Art, wie Daten präsentiert und interpretiert werden. Diese Fehler kosten Zeit, weil sie das eigentliche Signal verwässern.
- Zu viele Widgets auf einer Seite. Was wie Transparenz wirkt, erzeugt in Wahrheit Lärm.
- Keine Trennung von Live- und Verlaufsdaten. Ein Trend ist kein Status, und ein Status ist kein Trend.
- Unklare Zeithorizonte. Wenn nicht sichtbar ist, ob ein Chart 15 Minuten oder 15 Tage zeigt, wird jede Interpretation wacklig.
- Alarme ohne Priorität oder Besitzer. Eine Warnung ohne Zuständigkeit landet im Nirgendwo.
- Keine Rücksicht auf Verbindungsabbrüche. In schwachen Netzen braucht es Puffer, Wiederholung und klare Kennzeichnung von Ausfällen.
- Kein Drill-down. Eine Oberflächenansicht ohne Tiefenansicht zwingt Teams, sich andere Wege zu suchen.
- Keine Audit-Spur. Wenn Änderungen an Konfigurationen nicht nachvollziehbar sind, wird Fehlersuche unnötig teuer.
Ein gutes Design beseitigt diese Probleme nicht mit Dekoration, sondern mit Struktur. Ich reduziere, vereinheitliche und markiere nur das, was für Entscheidungen nötig ist. Danach stellt sich die Frage, welches Tool diesen Ansatz wirklich tragen kann.
Woran ich eine Plattform oder ein Tool bewerte
Ich entscheide nicht zuerst nach Marke, sondern nach Passung. Lösungen wie Azure IoT Central oder AWS IoT Device Management zeigen, wie viel Zeit ein gutes Bedienkonzept sparen kann, wenn Device-Management, Monitoring und Zugriffskontrolle bereits mitgedacht sind. Ein BI-Tool ist stark bei Auswertungen, aber oft schwach bei Geräteaktionen. Eine Eigenentwicklung ist flexibel, verlangt aber mehr Pflege und Disziplin.
| Option | Stärke | Schwäche | Sinnvoll, wenn |
|---|---|---|---|
| Fertige IoT-Plattform | Schnell startklar, oft mit Geräteverwaltung, Alarmierung und Rollenmodell | Weniger Freiheit im UI, Risiko von Lock-in | Wenn Zeit bis zum produktiven Betrieb kurz ist |
| BI- oder Analytics-Tool | Sehr gut für Reports, Trends und Management-Ansichten | Schwächer bei Echtzeit, Aktionen und Gerätesteuerung | Wenn Analyse wichtiger ist als operative Steuerung |
| Eigene Web-Anwendung | Passt exakt zu Prozessen, Datenmodell und Nutzerrollen | Mehr Entwicklungs- und Wartungsaufwand | Wenn die Abläufe einzigartig sind und sich selten standardisieren lassen |
Meine Auswahlkriterien sind immer dieselben: Lässt sich die Lösung an bestehende APIs anbinden? Gibt es rollenbasierten Zugriff? Sind Audit-Logs vorhanden? Kann ich Alarmregeln sauber definieren? Und vor allem: Ist die Oberfläche auch für Leute verständlich, die nicht jeden Tag mit der Technik arbeiten? Wenn diese Fragen mit Ja beantwortet werden, ist das Tool meist tragfähig. In verteilten Netzen kommt noch ein zusätzlicher Punkt dazu, und der ist oft entscheidend.
Was in verteilten Netzen den Unterschied macht
In Regionen mit schwankendem Mobilfunk, langen Backhaul-Strecken oder kleinen, weit verstreuten Standorten zählt nicht die schönste Visualisierung, sondern Robustheit. Ich würde dort drei Dinge zuerst absichern: lokales Puffern von Daten für mindestens 24 bis 72 Stunden, klare Priorisierung nach Standortkritikalität und eine getrennte Anzeige für „kein Signal“, „kein Messwert“ und „Messwert außerhalb des Bereichs“.
- Lokales Puffern verhindert Datenlücken, wenn die Verbindung kurzzeitig ausfällt.
- Priorisierte Alarme sorgen dafür, dass kritische Standorte nicht zwischen Routinewarnungen untergehen.
- Bandbreitenarme Übertragung reduziert unnötigen Verkehr und hält die Betriebskosten im Rahmen.
- Klar sichtbarer Verbindungszustand trennt Netzprobleme von Sensorproblemen.
- Saubere Synchronisation nach Wiederverbindung verhindert doppelte oder verlorene Ereignisse.
Für solche Umgebungen plane ich die Oberfläche konservativer als in einem stabilen Rechenzentrumsnetz. Das ist kein Nachteil, sondern Realität: Ein Dashboard soll den Betrieb auch dann lesbar halten, wenn die Verbindung nicht perfekt ist. Genau deshalb beginne ich bei neuen IoT-Projekten mit einer kleinen Flotte, zwei bis drei wirklich relevanten Alarmen und einer klaren Drill-down-Struktur. Erst wenn diese Basis stabil ist, erweitere ich um Trends, Rollen und Automatisierung. So bleibt die Oberfläche ein Werkzeug für Entscheidungen und wird nicht zur Sammlung hübscher, aber folgenloser Diagramme.