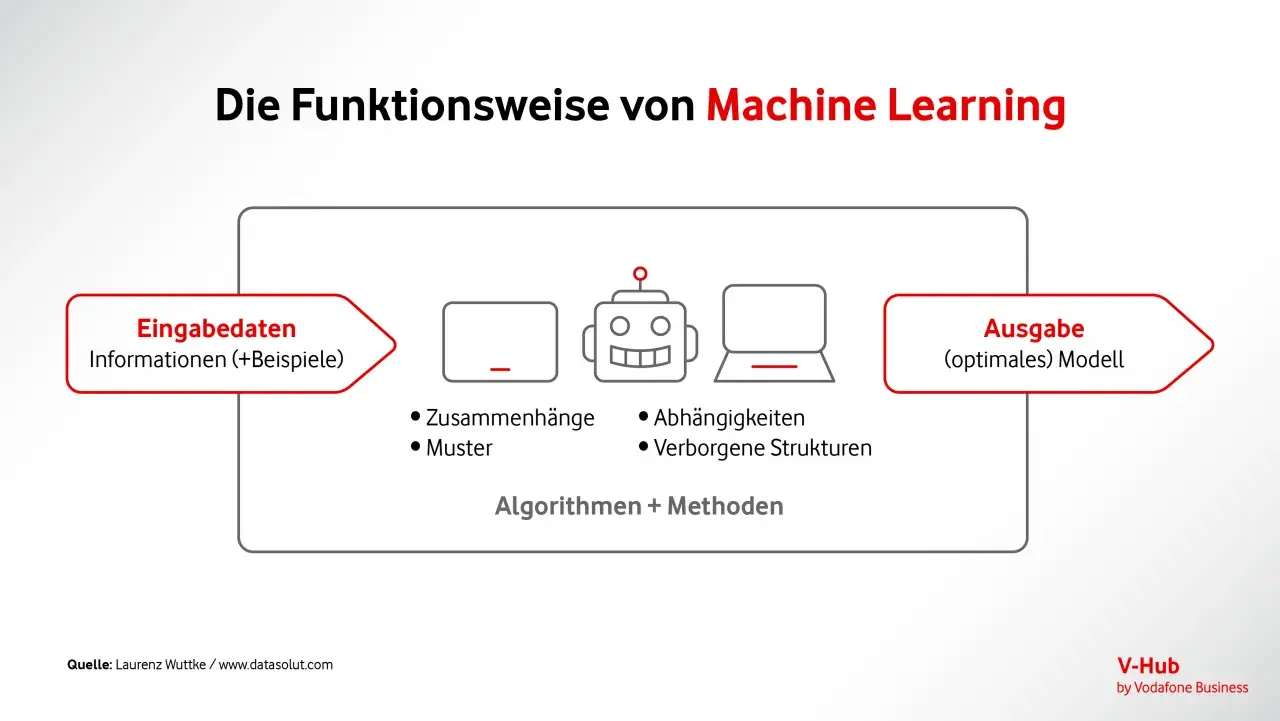
Vernetzte Geräte erzeugen permanent Telemetrie, aber erst mit lernenden Modellen werden daraus Entscheidungen: Störungen lassen sich früher erkennen, Wartungsfenster besser planen und unnötige Übertragungen vermeiden. Im Kern geht es bei iot machine learning darum, aus Rohdaten von Sensoren belastbare Signale zu machen, die im Betrieb wirklich etwas verändern. Ich konzentriere mich hier auf das, was in IoT-Systemen zählt: Datenqualität, Latenz, Edge-Verarbeitung und die Frage, wo sich der Aufwand tatsächlich rechnet.
Die wirksamsten IoT-Modelle sind klein, lokal verwertbar und auf saubere Daten gebaut
- Machine Learning bringt vor allem dann etwas, wenn Sensordaten in konkrete Aktionen übersetzt werden, etwa bei Anomalien, Prognosen oder Wartung.
- In vielen IoT-Systemen ist ein Hybrid aus Edge und Cloud sinnvoller als reine Cloud-Verarbeitung.
- Die Qualität von Zeitstempeln, Kalibrierung und Kontextdaten entscheidet oft stärker über den Erfolg als die Modellarchitektur.
- Wirklich robuste Lösungen messen nicht nur Modellgüte, sondern auch Fehlalarme, Latenz, Bandbreite und Offline-Fähigkeit.
- Gerade bei Infrastruktur- und Konnektivitätssystemen zählt, dass das System auch bei schwankender Verbindung weiterarbeiten kann.
Was lernende IoT-Systeme tatsächlich leisten
Ich würde lernende IoT-Systeme nie nur als „Datenanalyse“ beschreiben. Ihr eigentlicher Wert entsteht erst dann, wenn Sensorwerte, Ereignisse und Zustandsdaten so ausgewertet werden, dass eine Anlage, ein Netz oder ein Gerät besser reagiert als mit starren Regeln allein. Das kann bedeuten, dass ein Modell einen Ausfall früh erkennt, einen Verbrauch plausibilisiert oder zwischen normalem Betrieb und echtem Problem unterscheidet.
Praktisch sehe ich vier Aufgaben, für die sich ML im IoT besonders oft lohnt:
- Anomalieerkennung, wenn normale Muster bekannt sind und Abweichungen früh auffallen sollen.
- Klassifikation, wenn ein Zustand eindeutig zugeordnet werden muss, etwa „normal“, „warnungsrelevant“ oder „kritisch“.
- Prognosen, wenn Last, Verbrauch, Temperatur oder Ausfallwahrscheinlichkeit im Voraus geschätzt werden sollen.
- Optimierung, wenn ein System aus den Daten lernt, wie es sparsamer, stabiler oder reaktionsschneller arbeitet.
Wichtig ist dabei eine nüchterne Erwartung: Nicht jedes Problem braucht Deep Learning. In vielen IoT-Installationen ist ein sauberer Schwellenwert, ergänzt um wenige Regeln und ein leichtes Modell, robuster als ein kompliziertes neuronales Netz. Genau dort beginnt die praktische Qualität, nicht bei der Modellgröße. Welche Anwendungsfälle davon am meisten profitieren, zeigt sich am klarsten in den typischen Einsatzszenarien.
Wo Machine Learning in vernetzten Geräten sofort Nutzen bringt
In der Praxis tauchen immer wieder dieselben Felder auf, in denen lernende Modelle spürbar Mehrwert liefern. Besonders stark ist der Effekt dort, wo Ausfälle teuer sind, Reaktionszeiten kurz sein müssen oder Rohdaten zu viel Bandbreite kosten würden.
| Anwendungsfeld | Was das Modell erkennt oder verbessert | Warum das relevant ist |
|---|---|---|
| Telekommunikations- und Netzstandorte | Temperaturspitzen, Batterieprobleme, Netzteilausfälle, ungewöhnliche Lastmuster | Weniger ungeplante Ausfälle, schnellere Entstörung, bessere Planung von Wartungseinsätzen |
| Energie- und Wassersysteme | Leckagen, Druckabfälle, Lastspitzen, Pumpenverhalten | Frühere Störungserkennung und geringere Verluste im Betrieb |
| Logistik und Flotten | Abweichende Routen, Vibrationsmuster, Temperaturdrift, Standzeiten | Weniger Stillstand und bessere Auslastung von Fahrzeugen und Anlagen |
| Landwirtschaft und Umweltmonitoring | Bodenfeuchte, Bewässerungsbedarf, Gerätezustand, Wettereffekte | Gezielter Ressourceneinsatz statt pauschaler Steuerung |
| Gebäude und Campus-Infrastruktur | Ungewöhnlicher Energieverbrauch, Lüftungsprobleme, Belegungsmuster | Stabilerer Betrieb und spürbar effizientere Nutzung von Energie |
Für mich ist entscheidend, dass der Use Case nicht spektakulär klingt, sondern wirtschaftlich sauber ist. Ein Modell, das drei unnötige Vor-Ort-Einsätze pro Monat verhindert, ist oft wertvoller als ein viel komplexeres System, das zwar beeindruckend aussieht, aber im Alltag kaum Entscheidungen verändert. Genau deshalb kommt als Nächstes die Frage, welche Daten so ein Modell überhaupt tragen können.
Welche Daten ein brauchbares Modell wirklich braucht
Hier scheitern die meisten Projekte nicht an der Mathematik, sondern an der Datenbasis. Ein Sensor liefert erst dann verwertbare Signale, wenn Messung, Kontext und Zeitbezug zusammenpassen. Ohne das wird selbst ein gutes Modell schnell blind oder produziert zu viele Fehlalarme.
Zeitstempel und Kontext sind kein Luxus
Wenn Messwerte nicht sauber synchronisiert sind, vergleicht das Modell unter Umständen Werte, die in Wirklichkeit zeitlich versetzt entstanden sind. Das klingt banal, macht aber im Betrieb einen großen Unterschied. Gerade bei Temperatur, Vibration, Energieverbrauch oder Netztelemetrie kann eine kleine Verschiebung die Aussage komplett verfälschen.
Labels sind seltener als gedacht
Viele IoT-Daten sind zwar reichlich vorhanden, aber nicht sauber beschriftet. Für Anomalieerkennung ist das oft trotzdem kein K.-o.-Kriterium, weil man mit Normalverhalten und statistischen Mustern arbeiten kann. Für Klassifikationsaufgaben ist sauberes Labeling aber Pflicht, sonst lernt das Modell nur Zufall und Betriebsrauschen.
Lesen Sie auch: OPC UA im IoT - Mehr als nur Daten transportieren?
Drift ist kein Fehler, sondern der Normalfall
Sensoren altern, Standorte ändern ihr Umfeld, Firmware wird aktualisiert, Lastprofile verschieben sich mit Tageszeit und Saison. Ein Modell, das im Labor gut funktioniert, kann deshalb im Feld innerhalb weniger Wochen an Qualität verlieren. Ich plane deshalb von Anfang an Monitoring für Daten- und Konzeptdrift ein, nicht erst nach dem Rollout.
Ein belastbares Projekt braucht also mehr als nur Messwerte. Es braucht Kalibrierung, Metadaten, eine nachvollziehbare Definition von Ausreißern und einen Plan dafür, wie das Modell nach dem Start mit neuen Bedingungen umgeht. Wenn das steht, stellt sich die Architekturfrage, und die ist im IoT oft wichtiger als die Modellwahl selbst.
Cloud, Edge oder Hybrid was in der Praxis besser trägt
Die Entscheidung zwischen Cloud, Edge und Hybrid ist selten eine Glaubensfrage. Ich würde sie immer an drei Punkten aufhängen: Reaktionszeit, Bandbreite und Ausfallsicherheit. In Regionen mit schwankender Konnektivität oder bei entfernten Infrastrukturstandorten gewinnt deshalb häufig nicht die eleganteste, sondern die pragmatischste Architektur.
| Ansatz | Stärken | Grenzen | Wofür ich ihn wähle |
|---|---|---|---|
| Cloud | Starke Rechenleistung, zentrale Wartung, gute Skalierung | Abhängig von Verbindung, höhere Latenz, mehr Datenverkehr | Für Training, historische Analysen und nicht zeitkritische Auswertungen |
| Edge | Niedrige Latenz, lokale Autonomie, weniger Bandbreite | Begrenzte Rechenleistung, komplexere Gerätepflege | Für schnelle Entscheidungen, Offline-Betrieb und sensible Daten |
| Hybrid | Guter Kompromiss aus lokalem Betrieb und zentralem Lernen | Mehr Architektur- und Betriebsaufwand | Für die meisten produktiven IoT-Systeme mit echten Betriebsanforderungen |
Mein Standardgedanke ist simpel: Wenn die Entscheidung innerhalb von Sekundenbruchteilen oder bei instabiler Verbindung fallen muss, gehört mindestens ein Teil der Logik an den Rand des Netzes. Die Cloud bleibt dann für Training, Modellpflege und Langzeitauswertung zuständig. Genau daraus entsteht ein System, das nicht nur im Demo-Modus funktioniert, sondern auch im Alltag.
So würde ich ein Projekt Schritt für Schritt aufsetzen
Ich starte fast immer klein, weil ein sauberer Pilot mehr über die echte Tragfähigkeit eines Systems verrät als ein großer, schwer kontrollierbarer Rollout. Der beste Weg ist nicht, sofort das komplexeste Modell zu bauen, sondern zuerst die Reaktionskette zu klären: Welches Signal wird erkannt, wer oder was reagiert darauf, und was passiert, wenn das Modell irrt?
- Problem präzise formulieren: Nicht „wir wollen KI im IoT“, sondern zum Beispiel „wir wollen Ausfälle an einem Netzstandort 30 Minuten früher erkennen“.
- Dateninventur machen: Welche Sensoren gibt es, wie oft messen sie, welche Felder fehlen, und wie stabil sind die Geräte über Zeit?
- Eine Baseline bauen: Oft reicht zuerst ein einfaches Regelwerk oder ein leichtes Modell, um zu sehen, ob das Signal überhaupt vorhanden ist.
- Die Betriebsumgebung mitdenken: Latenz, Strombudget, Offline-Phasen und Wartungszugang müssen vor dem Modell stehen, nicht danach.
- Nur einen Piloten starten: Ein Standort, eine Linie, ein Gerätetyp oder ein eng abgegrenzter Prozess ist der bessere Anfang als ein kompletter Rollout.
- Monitoring und Retraining fest einplanen: Ohne Überwachung von Modellqualität, Fehlalarmen und Drift verschlechtert sich das System still und leise.
Dabei messe ich Erfolg nie nur an der reinen Vorhersagegenauigkeit. Für IoT-Projekte sind oft andere Kennzahlen wichtiger, weil sie näher am tatsächlichen Betrieb liegen.
| Kennzahl | Was sie zeigt | Worauf ich achte |
|---|---|---|
| Fehlalarmrate | Wie oft das System unnötig alarmiert | Zu viele Fehlalarme machen Betreiber schnell blind für echte Probleme |
| Trefferquote bei kritischen Ereignissen | Wie zuverlässig echte Störungen erkannt werden | Ein übersehenes Ereignis ist meist teurer als ein zusätzlicher Warnhinweis |
| Erkennungszeit | Wie schnell das Modell auf eine Veränderung reagiert | Besonders wichtig bei Infrastruktur, Energie und Remote-Standorten |
| Datenvolumen pro Gerät | Wie stark das Modell Funkstrecke und Backend belastet | Relevanz für Standorte mit knapper Bandbreite oder hohem Batteriebudget |
Wenn diese Kennzahlen nicht sauber gemessen werden, bleibt das Projekt eine schöne Theorie. Mit ihnen lässt sich dagegen ziemlich schnell erkennen, ob das System im Feld wirklich besser ist als der alte manuelle Ablauf. Von dort ist es nicht weit zu den Fehlern, die ich am häufigsten sehe.
Die typischen Fehler kosten meist mehr als das Modell
Die teuersten Probleme liegen selten im Algorithmus selbst. Sie entstehen meist dort, wo die Betriebsrealität ignoriert wird. Ich sehe in IoT-Projekten immer wieder dieselben Muster, und fast alle davon lassen sich früh entschärfen.
- Zu komplexer Start: Ein schweres Modell wird gewählt, obwohl noch unklar ist, ob der Datenstrom überhaupt ein brauchbares Signal trägt.
- Zu saubere Trainingsdaten: Das Labor sieht gut aus, aber im echten Feld tauchen Störungen, Ausfälle und Messfehler viel häufiger auf.
- Kein Umgang mit Drift: Das Modell wird einmal trainiert und dann monatelang nicht mehr überprüft.
- Falsche Annahmen über Konnektivität: Das System setzt ständige Erreichbarkeit voraus, obwohl der Standort offline oder nur zeitweise erreichbar ist.
- Kein Fallback: Wenn das Modell ausfällt, gibt es keinen klaren Ersatzpfad über Regeln oder manuelle Freigaben.
- Sicherheit erst am Ende: Geräteidentität, Updates, Schlüsselverwaltung und Segmentierung werden zu spät eingeplant.
Mein wichtigster Praxispunkt ist dabei dieser: Prognose ist nicht gleich Automatisierung. Ein Modell kann eine Wahrscheinlichkeit liefern, ohne selbst eine Steuerentscheidung treffen zu dürfen. Gerade bei kritischer Infrastruktur ist das keine Schwäche, sondern oft die vernünftigste Form von Kontrolle. Und genau deshalb muss auch die Konnektivität im nächsten Schritt genauso ernst genommen werden wie das Modell selbst.
Was ich vor dem Rollout noch einmal prüfe
Für IoT-Systeme mit Machine Learning entscheidet oft nicht die Modellqualität allein, sondern die Fähigkeit des gesamten Systems, unter echten Netz- und Betriebsbedingungen stabil zu bleiben. In entlegenen oder wechselhaft versorgten Regionen ist das besonders wichtig, weil Latenz, Ausfälle und Bandbreitenbegrenzungen direkt auf die Nutzbarkeit schlagen.
- Lokale Weiterarbeit: Kann das Gerät bei Verbindungsverlust weiter messen, bewerten und später synchronisieren?
- Passende Übertragung: Werden nur die Daten geschickt, die wirklich gebraucht werden, statt jede Rohmessung ungefiltert in die Cloud zu senden?
- Update-Fähigkeit: Lässt sich Modelllogik, Firmware und Sicherheitskonfiguration aus der Ferne sauber aktualisieren?
- Energiehaushalt: Passt das Modell zum Strombudget des Geräts, oder frisst es mehr als der Sensor selbst?
- Fallback im Betrieb: Gibt es klare Regeln, was passiert, wenn das Modell unsicher ist oder ausfällt?
Wenn ich ein Projekt auf seinen Kern reduziere, bleibt am Ende eine einfache Formel: Ein starkes IoT-System braucht nicht nur ein gutes Modell, sondern auch saubere Daten, eine passende Architektur und Konnektivität, die den Betrieb nicht ausbremst. Genau dort liegt der Unterschied zwischen einer interessanten Demo und einer Lösung, die Infrastruktur wirklich zuverlässiger macht.