Hinter dem oft unscharf verwendeten Begriff opc protocol steckt in der Praxis fast immer OPC UA, also der Standard für sicheren, herstellerübergreifenden Datenaustausch zwischen Maschinen, Steuerungen und IT-Systemen. Für IoT-Systeme ist das wichtig, weil hier nicht nur Werte übertragen werden, sondern auch Kontext, Struktur und Zugriffsrechte. Wer Anlagen vernetzt, braucht deshalb mehr als ein Transportprotokoll. Ich zeige hier, wie der Standard aufgebaut ist, wo er in Industrie- und Infrastrukturprojekten wirklich hilft und welche Grenzen man ernst nehmen sollte.
Die wichtigsten Punkte auf einen Blick
- OPC UA ist ein Industriestandard für sicheren, plattformunabhängigen Datenaustausch und nicht nur ein reines Transportprotokoll.
- Für IoT-Projekte sind besonders das Datenmodell, die Sicherheit und die Wahl zwischen Client-Server und PubSub entscheidend.
- PubSub eignet sich für verteilte Datenflüsse, MQTT für Broker-Szenarien und UDP für brokerlose Kommunikation im lokalen Netz.
- Der Standard ist stark, wenn Maschinen-, Edge- und Cloud-Welten sauber verbunden werden sollen.
- Wer nur auf Konnektivität schaut und Semantik, Zertifikate oder Interoperabilität ignoriert, baut schnell teure Umwege.
Was OPC UA im IoT praktisch leistet
Die OPC Foundation beschreibt OPC als Standard für den sicheren und zuverlässigen Austausch von Daten in der industriellen Automatisierung und darüber hinaus. Genau dieser Punkt macht den Standard für IoT-Systeme so interessant: Er transportiert nicht nur Messwerte, sondern auch Bedeutung. Eine Temperatur ist dann nicht einfach eine Zahl, sondern Teil eines Modells mit Einheit, Kontext, Zustand und Berechtigungen.
Für mich ist das der eigentliche Unterschied zu vielen leichten IoT-Protokollen. Dort bekommt man oft eine Nachricht, aber wenig Struktur. Bei OPC UA kommt die Information so an, dass Maschinen, Gateways, SCADA-Systeme, MES und Cloud-Anwendungen sie ohne ständiges Spezial-Mapping verstehen können. Der Standard reicht dabei von Embedded-Geräten bis zur Cloud-Infrastruktur und passt deshalb gut zu verteilten Anlagen, etwa in der Produktion, im Energiesektor oder bei Telekommunikationsstandorten.
Wichtig ist auch die Sicherheitsseite. OPC UA bringt Verschlüsselung, Authentifizierung und Auditierung nicht als nachträgliche Option mit, sondern als Teil des Konzepts. Gerade in IoT-Setups mit vielen Knoten ist das ein echter Vorteil, weil man Sicherheit dann nicht an jeder Schnittstelle neu improvisieren muss. Genau an diesem Punkt wird spannend, wie sich die Architektur im Betrieb aufteilt.
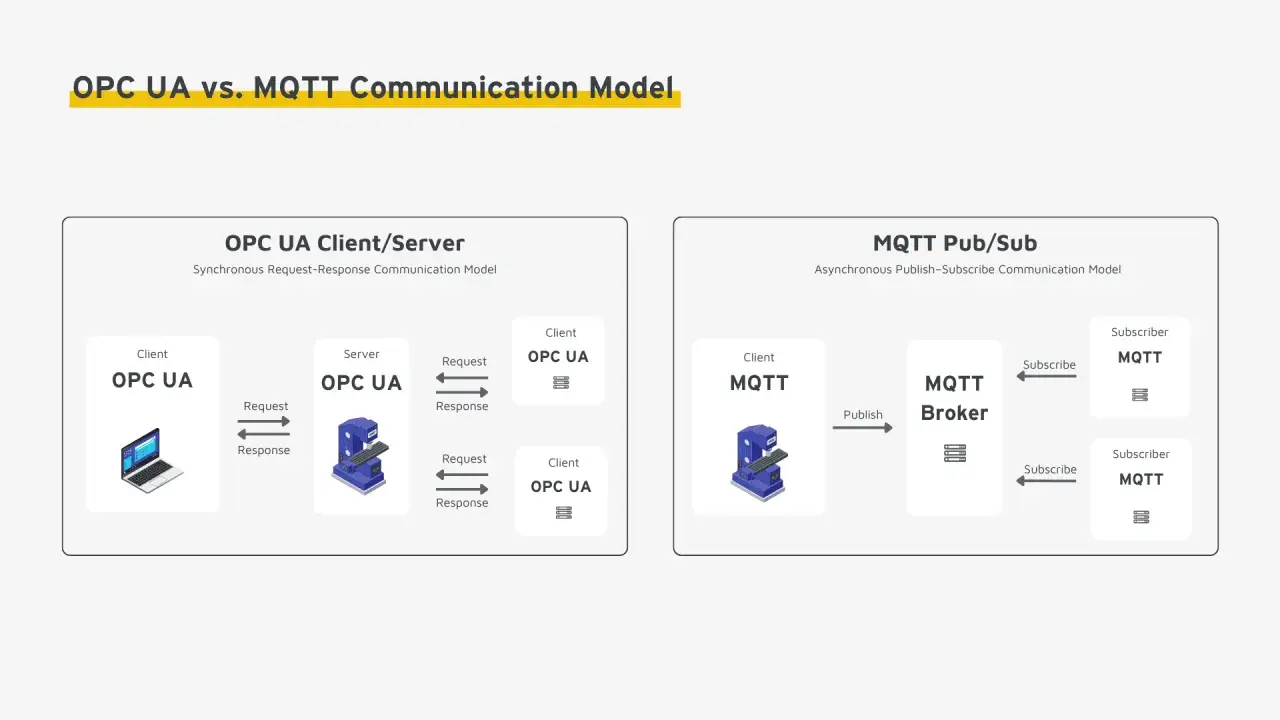
So unterscheiden sich Client-Server und PubSub
Bei IoT-Projekten entscheiden nicht nur Sensoren und Gateways über den Erfolg, sondern vor allem das Kommunikationsmuster. OPC UA kennt dafür zwei sehr unterschiedliche Logiken. Client-Server ist gut, wenn ein System gezielt Daten lesen, schreiben oder Diagnoseinformationen abrufen soll. PubSub ist stärker, wenn viele Teilnehmer dieselben Daten verteilten, entkoppelt und mit wenig Overhead nutzen sollen.
| Modell | Wofür es sich eignet | Stärken | Grenzen |
|---|---|---|---|
| Client-Server | HMI, Wartung, Diagnosen, punktuelle Abfragen | Einfach nachvollziehbar, präzise Zugriffe, gute Kontrolle | Weniger geeignet für breite Verteilung vieler Echtzeit-nahe Updates |
| PubSub über MQTT | Edge-to-Cloud, verteilte IoT-Daten, Broker-Szenarien | Sender und Empfänger sind entkoppelt, gut für skalierbare Verteilung | Abhängigkeit vom Broker, nicht für jede harte Echtzeitanforderung ideal |
| PubSub über UDP | Lokale Anlagenkommunikation, brokerlose Verteilung | Sehr direkt, schlank und für schnelle lokale Netze attraktiv | Braucht saubere Netzinfrastruktur und ist weniger bequem für übergreifende IT-Integration |
Die PubSub-Erweiterung ist in Teil 14 des Standards beschrieben. Praktisch heißt das: Ein Publisher sendet Daten an einen Broker oder direkt ins Netz, und mehrere Subscriber können sie parallel nutzen. MQTT ist dafür interessant, wenn Nachrichten gepuffert und über größere Strecken verteilt werden sollen. UDP passt eher in lokale Segmente, in denen man bewusst ohne Broker arbeitet. Die Wahl ist also keine Geschmacksfrage, sondern eine Frage der Betriebslogik.
Wenn ich ein IoT-Design bewerte, frage ich deshalb zuerst: Brauche ich direkte Abfragen, oder brauche ich eine verteilte Datenbewegung? Daraus ergibt sich meist schon die richtige Richtung für die Architektur. Im nächsten Schritt wird dann wichtig, wo der Standard in realen Projekten den größten Nutzen bringt.
Wo der Standard in IoT-Systemen stark ist
OPC UA ist nicht nur für die klassische Fabrikhalle spannend. Seine Stärke zeigt sich überall dort, wo heterogene Geräte, unterschiedliche Hersteller und mehrere Ebenen von OT und IT zusammenspielen. Gerade in Infrastrukturen mit wechselnder Konnektivität oder knapper Bandbreite zahlt sich die saubere Trennung von Semantik und Transport aus.
- Maschinen- und Linienintegration - Mehrere Anlagen lassen sich auf ein gemeinsames Informationsmodell abbilden, statt jeden Hersteller über eine neue Schnittstelle einzeln anzubinden.
- Verteilte Infrastruktur - Bei Energieanlagen, Wasserwerken oder Telekommunikationsstandorten hilft ein standardisiertes Modell, Zustände, Alarme und Messwerte über Standorte hinweg vergleichbar zu machen.
- Edge-to-Cloud-Pipelines - Daten können am Rand der Anlage vorverarbeitet und anschließend in Analytics-, Dashboard- oder Historisierungssysteme überführt werden.
- Wartung und Diagnose - Ein Engineer sieht nicht nur einen Wert, sondern auch Kontext, Zustände und Methoden, die für die Instandhaltung relevant sind.
- Semantische Anwendungen - Companion Specifications machen Daten maschinenlesbar im eigentlichen Sinn, also nicht nur syntaktisch korrekt, sondern fachlich eindeutig.
Das ist der Punkt, an dem viele IoT-Projekte unterschätzt werden. Telemetrie allein ist schnell integriert, aber ohne Semantik entsteht später Chaos bei Auswertung, Skalierung und Support. Genau deshalb ist der Standard dort besonders stark, wo aus Rohdaten verwertbare Betriebsinformationen werden sollen. Damit das in der Praxis nicht an der Umsetzung scheitert, braucht es einen sauberen Startpunkt.
Wie ich ein Projekt sinnvoll aufsetze
Ich würde ein OPC-UA-Projekt nie mit dem Protokoll beginnen, sondern mit dem Datenmodell. Erst wenn klar ist, welche Werte, Zustände und Ereignisse wirklich gebraucht werden, lohnt sich die Wahl von Client-Server, PubSub, MQTT oder UDP. Wer diesen Schritt überspringt, baut oft eine technisch saubere, aber fachlich umständliche Lösung.
- Daten und Rollen festlegen - Welche Signale werden gelesen, welche geschrieben, welche nur überwacht? Wer darf sie sehen?
- Das Informationsmodell bestimmen - Welche Objekte, Attribute, Events und Methoden gehören zusammen? Hier entscheidet sich, ob das System später verständlich bleibt.
- Die passende Kommunikationsart wählen - Client-Server für gezielte Interaktion, PubSub für Verteilung, MQTT für Broker-Netze und UDP für lokale brokerlose Szenarien.
- Sicherheit früh einplanen - Zertifikate, Rollen, Trust-Listen und Auditierung gehören in die Architektur, nicht in die Schlussphase.
- Edge und Ausfallszenarien berücksichtigen - Wenn Verbindungen instabil sind, braucht das lokale System Autonomie, Pufferung oder ein sauberes Store-and-forward-Konzept.
- Interoperabilität testen - Mehrere Hersteller, unterschiedliche Firmwarestände und reale Netzbedingungen zeigen oft schneller Schwächen als jede Spezifikation.
In der Praxis spare ich bei solchen Projekten am meisten Zeit, wenn ich die Schnittstellen nicht nur technisch, sondern auch betrieblich denke. Wer muss warten? Wer darf konfigurieren? Was passiert bei einem Zertifikatswechsel? Diese Fragen sind meist wichtiger als das nächste Feature. Und genau dort lauern auch die typischen Fehler.
Welche Fehler in der Praxis teuer werden
Der häufigste Irrtum ist, OPC UA nur als Ersatz für ein älteres Kabel- oder Treiberprotokoll zu sehen. Dann wird zwar verbunden, aber nicht wirklich standardisiert. Ein sauberer Informationsraum ist mehr wert als ein schneller Durchsatz, wenn später mehrere Anwendungen dieselben Daten nutzen sollen.
- Semantik ignorieren - Wer nur Werte, aber keine Bedeutung modelliert, erzeugt später doppelte Mapping-Arbeit.
- Sicherheit aufschieben - Zertifikate, Rollen und Laufzeiten werden oft zu spät bedacht, obwohl sie den Betrieb dauerhaft prägen.
- Zu viele Gateways stapeln - Jede Übersetzungsschicht kostet Latenz, Fehlerpotenzial und Wartungsaufwand.
- Echtzeit überschätzen - Für harte deterministische Steuerung reicht ein Standard-Setup nicht automatisch aus; dafür braucht es eine Architektur, die das Feldniveau wirklich mitdenkt.
- Cloud zuerst denken - Wer ohne lokale Pufferung plant, verliert bei schwankender Konnektivität schnell Daten oder Betriebsfähigkeit.
Gerade in verteilten Infrastrukturen, etwa bei Außenstandorten oder Netzen mit begrenzter Bandbreite, ist dieser letzte Punkt entscheidend. Ein System, das nur bei perfekter Verbindung funktioniert, ist kein robustes IoT-System. Deshalb lohnt sich auch ein Blick auf die aktuellen Entwicklungen rund um Edge, Cloud und semantische Modelle.
Was 2026 bei Edge, Cloud und semantischen Modellen zählt
2026 verschiebt sich der Fokus deutlich von reiner Konnektivität hin zu nutzbarer Semantik. Die aktuelle Cloud-Reference-Architecture der OPC Foundation zielt darauf, IT- und Cloud-Anwendungen enger mit industriellen Datenflüssen zu verbinden. Gleichzeitig wächst das Ökosystem an Companion Specifications und Informationsmodellen weiter; die Organisation spricht inzwischen von über 430 Informationsmodellen.
Für Betreiber ist das mehr als eine Zahl. Es bedeutet, dass Daten aus immer mehr Anwendungsfeldern ohne individuelle Sonderbrücken verfügbar werden. Wer heute sauber modelliert, kann diese Informationen später leichter in Dashboards, Analysen, digitale Produktpässe oder KI-gestützte Auswertungen übernehmen. Genau das ist der Punkt, an dem der Standard von einer reinen Schnittstelle zu einer Infrastruktur für industrielle Digitalisierung wird.
- Digitale Produktpässe - Ein konsistentes Datenmodell erleichtert die Weitergabe von Produkt- und Prozessinformationen über mehrere Wertschöpfungsstufen hinweg.
- Edge-Integration - Daten können näher an der Maschine validiert, gefiltert und bei Bedarf lokal vorgehalten werden.
- Semantische Suche und Automatisierung - Je besser die Modelle gepflegt sind, desto leichter lassen sich Informationen später automatisiert nutzen.
Das ist auch der Grund, warum ich bei neuen IoT-Vorhaben keine isolierte Protokollentscheidung treffe, sondern eine Architekturentscheidung. Wer den Datenraum sauber aufbaut, kann ihn später erweitern, ohne jedes Mal das Fundament neu zu gießen.
Worauf ich bei neuen IoT-Installationen heute setzen würde
Wenn ich ein neues Industrie- oder Infrastrukturprojekt bewerten müsste, würde ich vier Dinge zuerst absichern: das Datenmodell, die Sicherheitsarchitektur, die Betriebsumgebung am Edge und die Interoperabilität mit mindestens zwei realen Systemen. Diese Reihenfolge ist in der Praxis belastbarer als jede rein theoretische Protokoll-Debatte.
- Erst Modell, dann Transport - Das spart später Mapping- und Integrationskosten.
- Security von Beginn an mitdenken - Zertifikatsverwaltung ist kein Detail, sondern Teil des Lebenszyklus.
- Für Ausfälle planen - Lokale Autonomie und Pufferung sind in echten Netzen oft wichtiger als maximale Eleganz.
- PubSub gezielt einsetzen - Dort, wo viele Empfänger dieselben Daten brauchen, spielt es seine Stärken aus.
- Komplexität begrenzen - Ein gutes Modell mit wenig sauberer Technik ist besser als ein verschachteltes Gateway-System mit vielen Workarounds.
Wer diesen Ansatz verfolgt, nutzt OPC UA nicht nur als Kommunikationsweg, sondern als stabile Grundlage für skalierbare IoT-Systeme. Genau darin liegt der praktische Wert: Maschinen, Infrastruktur und Cloud sprechen eine gemeinsame Sprache, ohne dass man für jeden neuen Anwendungsfall wieder von vorn anfangen muss.