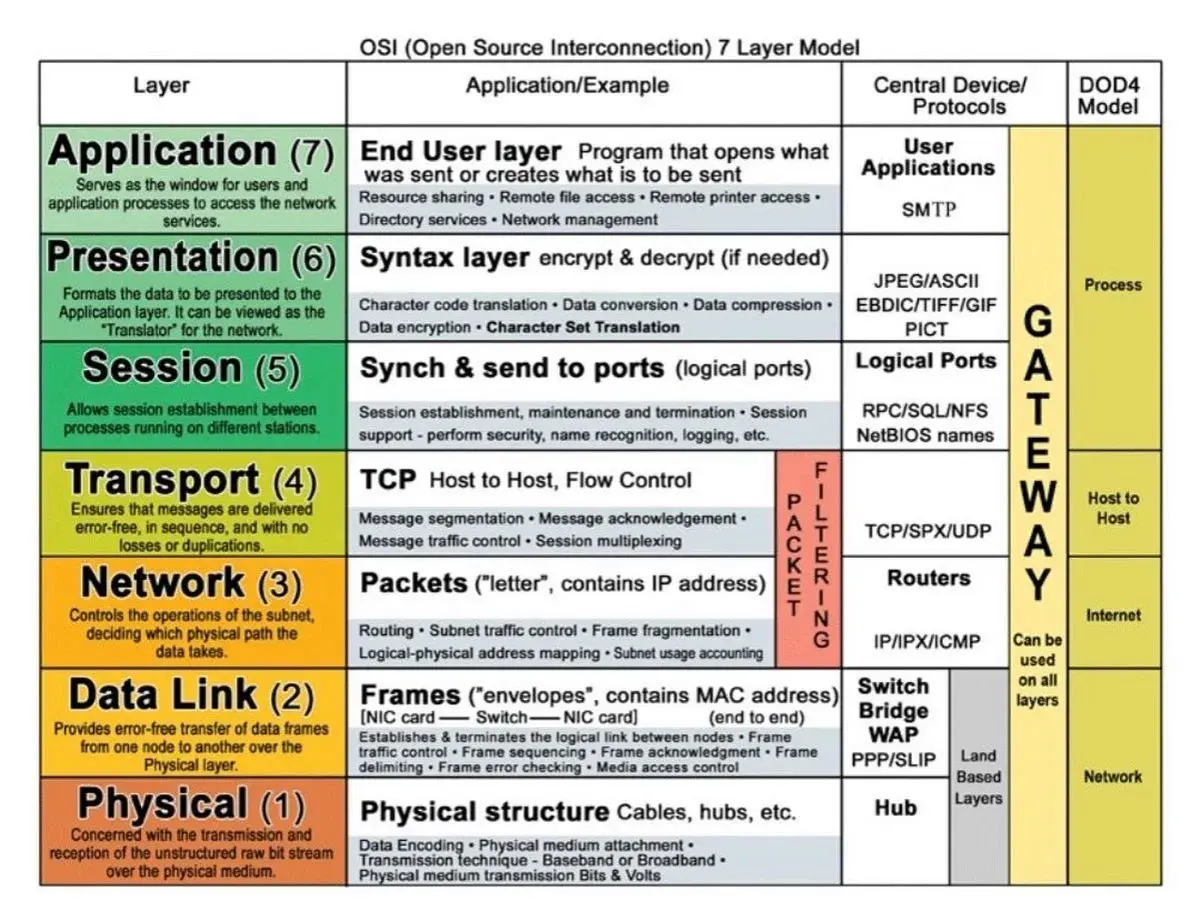
Ein protocol stack ist der Schichtenaufbau, der Daten durch ein Netz führt, ohne dass jede Komponente alles über den gesamten Weg wissen muss. Genau dieses Prinzip macht moderne Netzwerke wartbar, skalierbar und in der Praxis überhaupt erst beherrschbar. Wer Verbindungen plant, betreibt oder Fehler sucht, versteht mit diesem Modell schneller, warum etwas funktioniert oder scheitert.
Die Schichten sorgen dafür, dass Daten kontrolliert, austauschbar und prüfbar durchs Netz laufen
- TCP/IP arbeitet in vier Schichten; das OSI-Modell trennt das Thema in sieben Ebenen.
- Jede Schicht erfüllt eine klar umrissene Aufgabe und versteckt Details der darunterliegenden Ebene.
- TCP steht für Zuverlässigkeit, UDP für geringeren Overhead und oft weniger Latenz.
- Viele Störungen sitzen nicht in der Anwendung, sondern in DNS, Routing, MTU, Funkstrecke oder Firewall.
- Je knapper die Infrastruktur, desto wichtiger werden saubere Schichtgrenzen und gutes Monitoring.
Was ein Protokollstapel im Netzwerk tatsächlich leistet
Ein Protokollstapel ist keine akademische Spielerei, sondern eine Arbeitsteilung. Die Anwendung muss nicht wissen, ob darunter Glasfaser, LTE, Richtfunk oder Ethernet läuft; sie bekommt nur eine definierte Dienstleistung von der nächsten Schicht.
Ich trenne Netzwerke deshalb konsequent in Schichten, weil sich so zwei Dinge viel leichter lösen lassen: Änderungen und Fehlersuche. Tausche ich die Zugangsart aus, muss ich nicht die ganze Anwendung neu schreiben. Und wenn eine Verbindung hängt, kann ich prüfen, ob das Problem bei Adresse, Transport, Routing oder der physischen Strecke liegt.
Genau das macht das Modell in großen Netzen, in Unternehmensumgebungen und in abgelegenen Infrastrukturen so wertvoll: Die Komplexität verschwindet nicht, aber sie wird beherrschbar. Im nächsten Schritt lohnt sich der Blick darauf, wie die einzelnen Ebenen beim Versand einer Nachricht zusammenarbeiten.
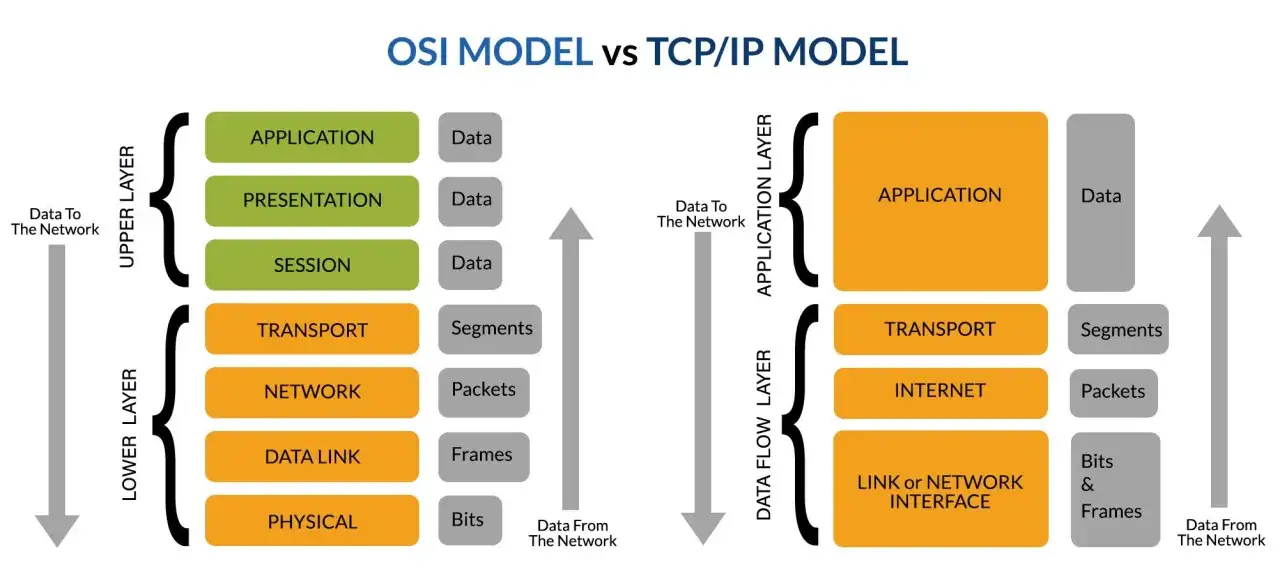
So greifen die Schichten beim Senden wirklich ineinander
Wenn eine Anwendung Daten verschickt, wandern sie von oben nach unten durch den Stapel. Auf dem Weg werden sie mehrfach verpackt, mit Steuerinformationen ergänzt und an die jeweilige Aufgabe der Schicht angepasst.
Anwendungsschicht
Hier entsteht der eigentliche Inhalt: eine Webseite, ein DNS-Request, eine VoIP-Anfrage oder ein Dateitransfer. Protokolle wie HTTP, DNS oder SMTP definieren, was übertragen werden soll und wie beide Seiten die Bedeutung der Daten verstehen.
Transportschicht
Auf dieser Ebene entscheiden TCP und UDP, wie die Daten transportiert werden. TCP nummeriert Segmente, bestätigt den Empfang und sendet verlorene Daten erneut; UDP verzichtet auf diese Sicherungen und spart dafür Overhead, was bei Echtzeitverkehr oder einfachen Anfragen nützlich sein kann.
Netzschicht
IP sorgt dafür, dass Pakete zwischen Netzen geroutet werden. Die Schicht arbeitet nach dem Best-Effort-Prinzip: Sie versucht den Transport, garantiert ihn aber nicht. Genau deshalb sind Adressierung, Routing und saubere Wege zwischen Teilnetzen so wichtig.
Lesen Sie auch: Communication Channels: Netzwerke richtig planen & verstehen
Linkschicht
Hier geht es um den nächsten Hop: Ethernet, WLAN, Mobilfunkzugang oder andere lokale Übertragungsverfahren. Diese Schicht kümmert sich um Frames, MAC-Adressen und die konkrete physische oder funktechnische Zustellung. Wenn hier Fehler entstehen, sieht alles darüber oft nur wie ein „Internetproblem“ aus, obwohl die Ursache viel näher sitzt.
Beim Versand wandert die Nutzlast also von oben nach unten: aus Anwendungsdaten werden Segmente, daraus IP-Pakete und schließlich Frames. Genau diese Kapselung ist der Grund, warum ein sauber aufgebauter Stack so gut warten lässt. Der Unterschied zwischen dem theoretischen Modell und dem realen TCP/IP-Betrieb wird damit deutlich greifbarer.
TCP/IP und OSI im direkten Vergleich
Für den Betrieb ist das TCP/IP-Modell das wichtigere Werkzeug, weil es direkt mit realen Protokollen arbeitet. Das OSI-Modell bleibt trotzdem nützlich, weil es die Denkarbeit sauber trennt und Fehlerbilder ordnet.
| Kriterium | OSI-Modell | TCP/IP-Modell |
|---|---|---|
| Ebenenanzahl | 7 Schichten | 4 Schichten |
| Hauptzweck | Verständnis, Planung, Didaktik | Reale Protokolle und echte Implementierungen |
| Praxisnähe | Sehr gut zum Erklären und Strukturieren | Sehr gut für Betrieb, Konfiguration und Tests |
| Fehlersuche | Hilft beim Eingrenzen nach Ebenen | Hilft beim konkreten Prüfen von Protokollen und Pfaden |
| Typische Nutzung | Schulung, Analyse, Architekturgespräche | Netzdesign, Troubleshooting, Dokumentation |
Ich nutze OSI vor allem zum Erklären und Eingrenzen, TCP/IP dagegen zum Konfigurieren, Testen und Dokumentieren. Wer beide Modelle sauber auseinanderhält, spart sich viele Diskussionen, die sonst nur am Begriff hängen bleiben. Der nächste Punkt ist die Frage, warum das gerade bei knapper Bandbreite oder instabilen Leitungen so relevant wird.
Warum der Aufbau in Netzen mit knapper Infrastruktur so wichtig ist
In Netzen mit langen Strecken, Funkzügen, satten Latenzen oder begrenztem Backhaul wird jede Schicht spürbar. Ein paar Millisekunden mehr Verzögerung sind kein Drama; aber Paketverlust, schwankende Laufzeiten und falsche MTU-Werte summieren sich schnell zu echten Nutzungsproblemen.
Gerade in Insel- und Regionalnetzen, in denen Mobilfunk, Richtfunk oder Satellitenstrecken zusammenkommen, zeigt sich das besonders deutlich. Für Betreiber und Integratoren in solchen Umgebungen, auch in Timor-Leste, ist die Schichtenlogik deshalb kein Lehrbuchdetail, sondern ein Werkzeug für stabile Verbindungen.- Latenz verlängert Handshakes und Bestätigungen. Interaktive Dienste fühlen sich dann träge an, auch wenn die nominelle Bandbreite hoch aussieht.
- Paketverlust bremst TCP stärker als viele erwarten, weil Wiederholungen und Congestion Control sofort greifen.
- Jitter trifft Sprach- und Videodienste härter als Dateiübertragungen, weil konstante Laufzeiten dort wichtiger sind als reiner Durchsatz.
- MTU- und MSS-Fehler fallen oft erst auf, wenn größere Datenmengen oder bestimmte Zielnetze betroffen sind. Eine klassische Ethernet-MTU von 1500 Byte reicht eben nicht automatisch für jeden Tunnel oder jeden Pfad.
Ich halte deshalb wenig von pauschalen „Das Netz ist langsam“-Diagnosen. Erst wenn klar ist, ob die Verzögerung in der Funkstrecke, im Routing, im Transport oder in der Anwendung entsteht, lässt sich die passende Maßnahme wählen. Genau an dieser Stelle wird der Schichtenaufbau vom Lehrbuch zur Betriebspraxis.
Wo Fehler entstehen und wie ich sie eingrenze
Die schnellste Fehlersuche folgt einer einfachen Regel: erst die Schicht, dann das Symptom. Wer sofort an der Anwendung dreht, übersieht oft den eigentlichen Engpass darunter.
| Symptom | Wahrscheinliche Ebene | Erster Check |
|---|---|---|
| WLAN verbunden, aber kein Internet | Link- oder Netzschicht | Signalqualität, Access Point, DHCP, Gateway, Default Route |
| Ping zum Router klappt, Webseiten nicht | Anwendungs- oder Namensauflösung | DNS, Resolver, Cache, Filterregeln, Zielerreichbarkeit |
| Große Transfers brechen ab | Transport- oder Netzschicht | MTU, MSS, Fragmentierung, Pfad-MTU-Erkennung |
| Nur bestimmte Ziele sind langsam | Routing oder externer Pfad | Traceroute, Peering, Latenz, Verlust, asymmetrische Wege |
| Sprache stockt, Dateien laden aber normal | Transport und Anwendung | Jitter, Paketverlust, QoS, Pufferung, Echtzeit-Parameter |
Ein häufiger Sonderfall ist blockiertes ICMP. Dann scheitert die Pfad-MTU-Erkennung oft still, und große Pakete verschwinden scheinbar „einfach so“. Solche Fehler sind typisch für Netze, die gewachsen sind, aber nie sauber dokumentiert wurden. Deshalb lohnt sich immer ein Blick auf die Protokollgrenzen, bevor man am Applikationsserver sucht.
Worauf es bei einem stabilen Stack im Alltag ankommt
Ein belastbarer Stack entsteht nicht durch mehr Protokolle, sondern durch Klarheit an den richtigen Stellen. Ich setze in der Praxis auf wenige, aber konsequent dokumentierte Grundregeln:
- Adressen, Routing und DNS gehören dokumentiert, nicht nur inventarisiert.
- MTU und MSS sollten an Übergängen bewusst geprüft werden, besonders bei VPNs und Mischumgebungen.
- Monitoring muss mehr messen als Durchsatz: Latenz, Verlust, Jitter und Antwortzeit sind mindestens ebenso wichtig.
- Redundanz gehört an echte Engpässe, nicht reflexhaft überallhin.
- Neue Protokolle sollten auf dem realen Pfad getestet werden, bevor sie produktiv laufen.
Für Insel- und Regionalnetze zahlt sich diese Disziplin besonders aus, weil Entfernungen, Funkstrecken und knappe Kapazitäten jede Schwäche sofort sichtbar machen. Ein sauber gedachter Protokollstapel macht Netze nicht perfekt, aber deutlich nachvollziehbarer, und genau das ist im Betrieb oft der entscheidende Vorteil.