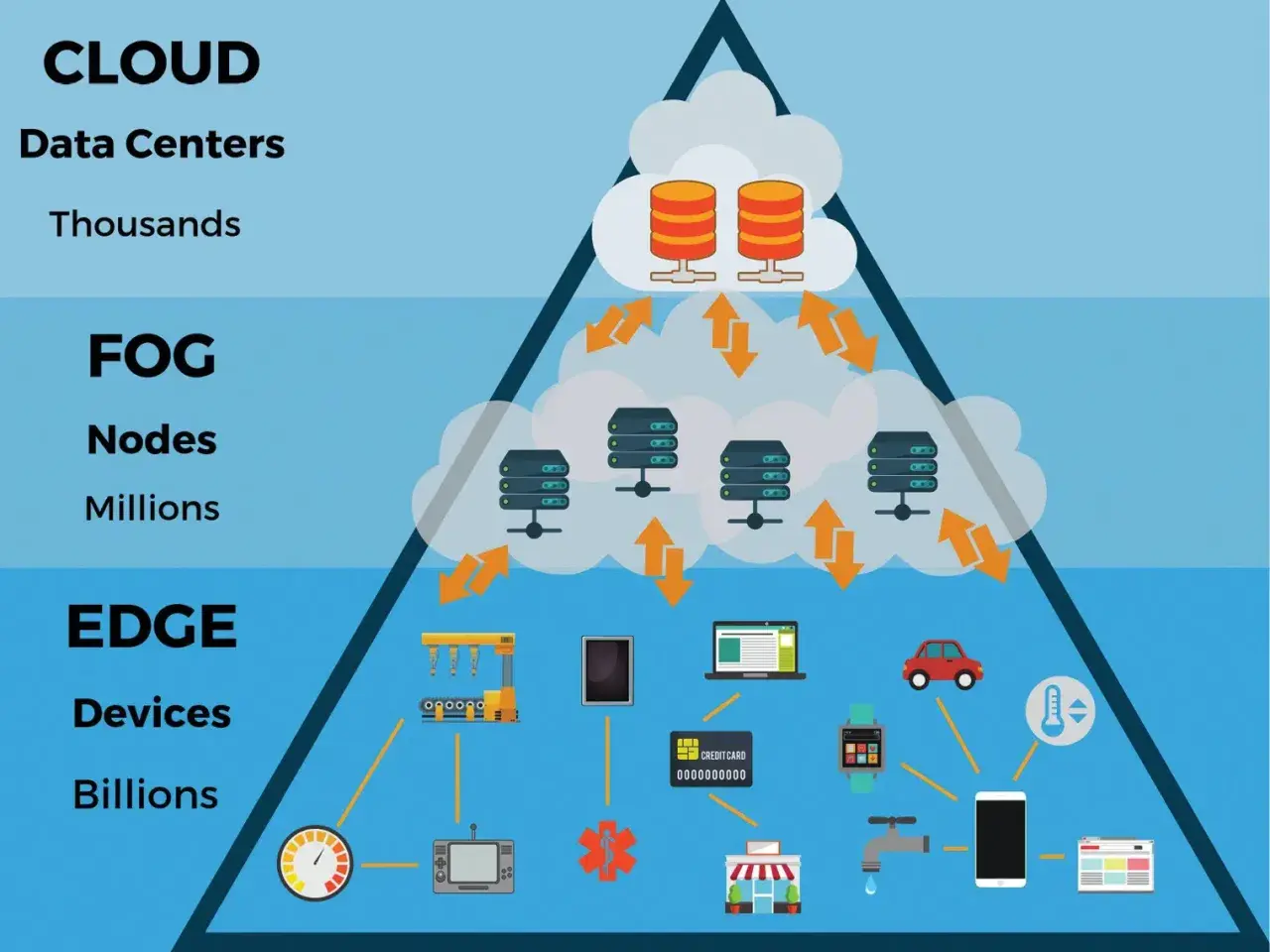
Bei IoT-Systemen entscheidet die Position der Rechenleistung oft mehr als das einzelne Gerät selbst. Wer Daten direkt am Sensor oder Gateway verarbeitet, gewinnt Tempo und Unabhängigkeit; wer mehrere Randknoten koordiniert, bekommt Übersicht, Stabilität und bessere Kontrolle über verteilte Standorte. Genau darum geht es hier: um die praktische Abgrenzung zwischen Edge- und Fog-Architekturen, ihre Stärken, ihre Grenzen und die Frage, welche Lösung in einem echten Netzbetrieb am Ende mehr trägt.
Die zentralen Unterschiede auf einen Blick
- Edge Computing verarbeitet Daten möglichst nah an der Quelle, also direkt am Gerät oder am lokalen Gateway.
- Fog Computing ergänzt diese Nähe um eine verteilte Zwischenschicht, die mehrere Edge-Knoten koordiniert.
- Der Unterschied ist in der Praxis oft kein harter Schnitt, sondern ein Kontinuum aus Gerät, Randknoten, lokaler Aggregation und Cloud.
- Edge ist stark bei Reaktionszeit und Autonomie, Fog bei Koordination, Vorfilterung und standortübergreifender Steuerung.
- In Netzen mit knapper oder instabiler Anbindung ist ein hybrider Aufbau meist robuster als ein reiner Cloud-Ansatz.
Was Edge Computing in IoT-Systemen wirklich macht
Ich verstehe Edge Computing als die Entscheidung, Rechenarbeit so nah wie möglich an den Ort der Datenerzeugung zu ziehen. Das kann auf dem Sensor selbst passieren, auf einer SPS, auf einem Industrie-Gateway oder auf einem kleinen Server im Schaltschrank. Der Vorteil ist schlicht: Die Anlage reagiert sofort, statt erst Daten in eine entfernte Plattform zu schicken und auf eine Antwort zu warten.Gerade bei IoT-Systemen zählt das, wenn eine Aktion im einstelligen Millisekundenbereich stattfinden muss oder wenn die Verbindung zum Kernnetz nicht zuverlässig genug ist. Typische Fälle sind Maschinenüberwachung, lokale Fehlererkennung, Zugangskontrollen, Energieverteilung oder Kameras, die nicht jeden Rohdatenstrom in die Cloud kippen sollen. Ich setze Edge besonders dort ein, wo ein Standort auch ohne Netzverbindung handlungsfähig bleiben muss.
Die Grenzen sind ebenfalls klar: Je mehr Intelligenz am Rand läuft, desto wichtiger werden Gerätemanagement, Updates, Versionskontrolle und Sicherheit. Ein einzelner Edge-Knoten ist überschaubar, eine Flotte aus 50 oder 500 Knoten wird schnell ein Betriebsproblem, wenn niemand Observability, also die saubere Sicht auf Logs, Metriken und Fehlerbilder, ernst nimmt. Genau dort beginnt der Übergang zur nächsten Ebene.
Was Fog Computing zusätzlich übernimmt
Fog Computing geht einen Schritt weiter als reine Randverarbeitung. Ich halte mich bei der Abgrenzung gern an die NIST-Logik: Fog ist kein zweiter Name für Edge, sondern eine zusätzliche, verteilte Schicht zwischen den Geräten und der Cloud. Dort werden Daten mehrerer Standorte gesammelt, verdichtet, zwischengespeichert und nach Regeln verteilt, statt alles ungeordnet nach oben zu schicken.
Das ist besonders nützlich, wenn mehrere Edge-Knoten gemeinsam betrachtet werden müssen. Ein einzelner Sensor kann an der Quelle entscheiden, aber ein Netz aus Sensoren, Gateways und lokalen Diensten braucht oft Koordination. Genau dafür ist Fog stark: Es hält Policies konsistent, puffert Daten bei Ausfällen und ermöglicht regionale Analytik, ohne die Cloud mit Rohdaten zu fluten. Einige Modelle kennen noch eine zusätzliche Mist-Ebene direkt am Gerät, aber für die meisten realen Projekte reicht die praktische Trennung zwischen Edge, Fog und Cloud.
Ich sehe Fog vor allem dort, wo ein Standort nicht isoliert ist, sondern Teil eines Verbunds: mehrere Funkmasten, verteilte Messstationen, Produktionshallen, Logistikketten oder Versorgungsinfrastruktur. In solchen Umgebungen zählt nicht nur Geschwindigkeit, sondern auch die Fähigkeit, mehrere Knoten synchron zu halten. Um das sauber einzuordnen, hilft ein direkter Vergleich auf Architekturebene.
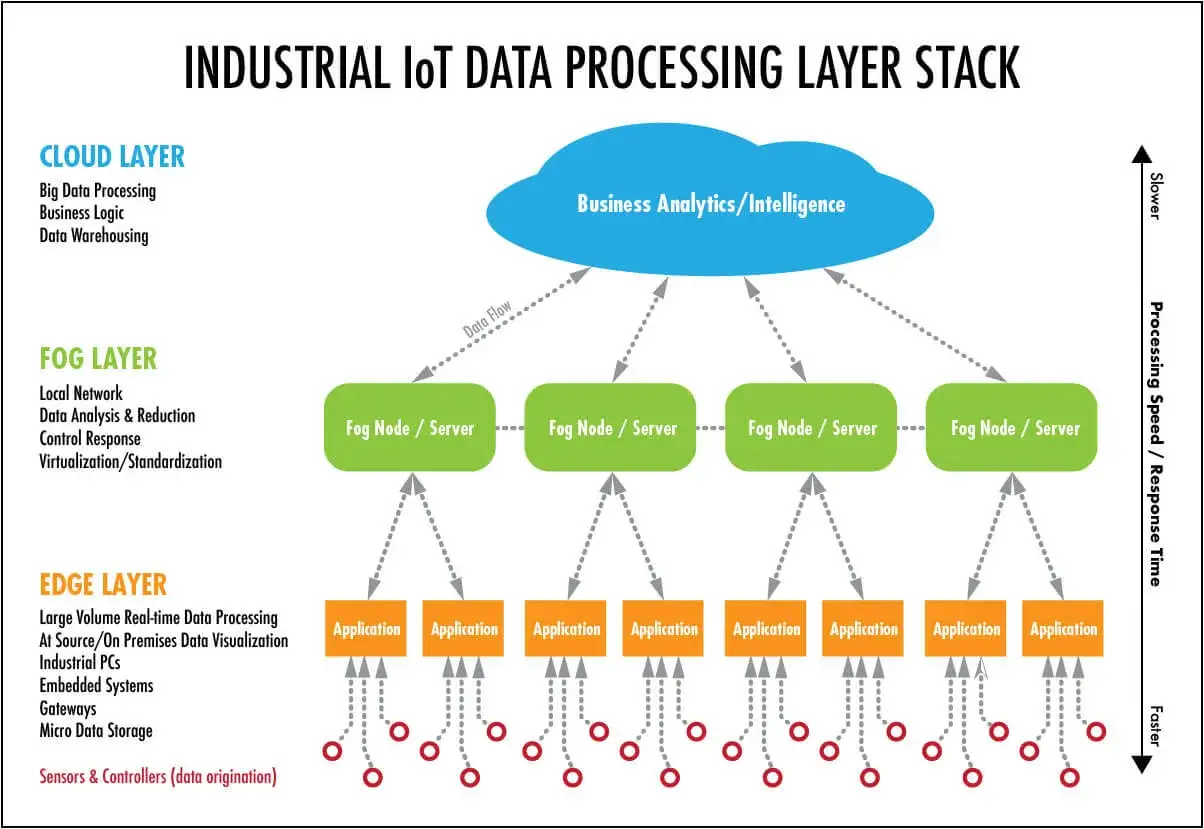
Fog und Edge in der Praxis auseinanderhalten
| Kriterium | Edge Computing | Fog Computing |
|---|---|---|
| Nähe zur Datenquelle | Direkt am Gerät oder am lokalen Gateway | Zwischen mehreren Edge-Knoten und der Cloud |
| Hauptaufgabe | Sofort handeln, filtern, reagieren | Koordinieren, aggregieren, zwischenspeichern |
| Latenz | Am niedrigsten | Sehr niedrig, aber mit zusätzlicher Zwischenschicht |
| Bandbreite | Reduziert Rohdaten am Ort der Entstehung | Reduziert zusätzlich standortübergreifend Datenvolumen |
| Betriebsmodell | Viele autonome Knoten | Hierarchische oder föderierte Steuerung |
| Stärke | Reaktionsgeschwindigkeit und Unabhängigkeit | Übersicht, Konsistenz und regionale Orchestrierung |
| Typisches Risiko | Verteilte Wartung und viele Einzelpunkte | Mehr Architektur- und Integrationsaufwand |
Mein Kurzsatz dazu lautet: Edge reagiert, Fog organisiert. In echten Projekten verschwimmt die Grenze aber schnell, weil viele Hersteller ihre Gateways bereits als Edge vermarkten, obwohl dort schon fogartige Funktionen laufen. Deshalb ist die Bezeichnung zweitrangig. Entscheidend ist, wo gefiltert wird, wo Regeln durchgesetzt werden und wo das System auch bei Verbindungsproblemen weiterarbeiten muss.
Wann Edge die bessere Wahl ist
Edge ist die richtige erste Wahl, wenn die lokale Entscheidung wichtiger ist als die regionale Übersicht. Ich denke dabei an Anlagen, die ohne Verzögerung reagieren müssen: eine Pumpe, die bei Trockenlauf abschaltet, eine Kamera, die nur bei einem Ereignis ein Alarmereignis auslöst, oder ein Zugangssystem, das keine Cloud-Runde abwarten darf, bevor es eine Tür freigibt.
- Wenn Reaktionszeit Vorrang vor zentraler Koordination hat.
- Wenn die Verbindung ins Kernnetz teuer, langsam oder instabil ist.
- Wenn sensible Daten das lokale Umfeld möglichst nicht verlassen sollen.
- Wenn der Anwendungsfall auf einem einzelnen Standort sauber lösbar ist.
Ich bevorzuge Edge auch dann, wenn der technische Umfang noch klein genug ist, dass ein lokaler Stack überschaubar bleibt. Ein einzelner Standort, ein klares Gerät, ein klarer Regelkreis: Das ist ein guter Edge-Fall. Sobald mehrere Standorte gemeinsam gesteuert werden sollen, lohnt sich der Blick auf die nächste Ebene.
Wann Fog mehr Sinn ergibt
Fog lohnt sich dort, wo einzelne Edge-Knoten für sich genommen zu wenig Überblick haben. Das ist typisch für Telekommunikationsstandorte, industrielle Außenstellen, regionale Energieinfrastruktur oder verteilte Sensornetze, die gemeinsam ausgewertet werden müssen. Die Schicht zwischen Gerät und Cloud kann Daten verdichten, lokale Regeln ausrollen und Lastspitzen abfangen, bevor sie das Backhaul, also die Verbindung vom Standort ins Kernnetz, unnötig belasten.
- Wenn mehrere Standorte dieselben Richtlinien und Datenflüsse brauchen.
- Wenn lokale Daten vor der Cloud zu Ereignissen oder Kennzahlen verdichtet werden sollen.
- Wenn bei Netzausfällen Pufferung und Wiederanlauf sauber funktionieren müssen.
- Wenn Standorte regional zusammenhängen, aber nicht permanent direkt mit der Cloud sprechen sollten.
In solchen Szenarien sieht man den eigentlichen Wert von Fog: nicht als Ersatz für Edge, sondern als Koordinationsschicht. Für mich ist das vor allem dann stark, wenn Betriebsteams nicht jeden Knoten einzeln managen wollen, sondern Richtlinien, Updates und Auswertungen regional bündeln müssen. Genau an dieser Stelle passieren die häufigsten Planungsfehler.
Typische Planungsfehler bei verteilten IoT-Netzen
Ich sehe in Projekten immer wieder dieselben Irrtümer. Der häufigste: Edge und Fog werden als Marketingbegriffe behandelt, statt die Workload sauber zu analysieren. Dann läuft am Ende alles halb lokal, halb zentral, aber niemand kann erklären, warum genau diese Aufteilung gewählt wurde.
- Rohdaten werden unnötig in die Cloud geschickt, obwohl lokale Vorfilterung gereicht hätte.
- Jeder Gateway wird zum Mini-Server gemacht, ohne dass es ein sauberes Lifecycle-Management gibt.
- Offline-Fähigkeit wird geplant, aber nie wirklich getestet.
- Sicherheitszonen, Zertifikate und Patch-Prozesse werden auf verteilten Knoten zu spät bedacht.
- Observability fehlt, sodass Störungen erst auffallen, wenn schon Daten fehlen oder Geräte ausfallen.
Am problematischsten ist meist nicht die Technik selbst, sondern die Annahme, dass lokale Intelligenz automatisch leichter zu betreiben sei als eine zentrale Plattform. Das Gegenteil kann stimmen. Ein Edge-Feld mit vielen Geräten verlangt Disziplin, und eine Fog-Schicht verlangt Architekturkompetenz. Wer diese Kosten unterschätzt, baut sich unnötig Komplexität ein, gerade in Netzen mit ungleichmäßiger Konnektivität.
Warum knappe Konnektivität die Architekturentscheidung verschiebt
In Umgebungen mit knapper oder unzuverlässiger Anbindung verändert sich die Gewichtung deutlich. Das gilt für ländliche Netze, für Insel- und Küstenregionen, für abgelegene Industrieflächen und auch für Telekommunikationsinfrastruktur, die nicht überall dieselbe Backhaul-Qualität hat. Gerade in einem Umfeld wie Timor-Leste ist das kein theoretisches Detail: Wenn Standorte weit auseinanderliegen und Verbindungen nicht permanent stabil sind, muss das System zuerst lokal überleben können.
Hier spielt Edge seine Stärke aus, weil es den laufenden Betrieb am Standort sichert. Fog ergänzt das um die Fähigkeit, mehrere entfernte Punkte dennoch gemeinsam zu steuern, Daten regional zu puffern und nur das wirklich Relevante weiterzuleiten. Ich halte das für die robusteste Mischung, wenn Anbindung nicht selbstverständlich ist und Ausfälle real mitgedacht werden müssen.
Der praktische Schluss ist einfach: Je teurer oder unsicherer die Verbindung, desto weniger sinnvoll ist es, jede Entscheidung zentral zu erzwingen. Dann wird lokale Autonomie wichtiger, aber ohne eine koordinierende Zwischenschicht verliert das Netz schnell den Überblick. Mit einer sauberen Aufteilung lässt sich beides verbinden.
Wie ich zwischen beiden Ansätzen in 2026 entscheide
Wenn ich ein IoT-Design bewerte, gehe ich in dieser Reihenfolge vor:
- Kann der Standort auch ohne stabile Verbindung sicher und sinnvoll weiterarbeiten?
- Müssen mehrere Standorte gemeinsam ausgewertet oder gesteuert werden?
- Wie teuer ist jeder unnötige Datenstrom über das Netz?
- Wie viel Betriebsaufwand verträgt das Team bei Updates, Monitoring und Sicherheit?
- Gibt es eine klare Aufgabe für die Cloud, die über Archivierung und schwere Analytik hinausgeht?
Wenn die erste Frage dominiert, starte ich mit Edge. Wenn die Fragen zwei bis fünf wichtiger werden, setze ich Fog darüber. Für 2026 ist die robusteste Antwort in den meisten IoT-Systemen kein Entweder-oder, sondern ein abgestuftes Modell: Edge für die schnelle Reaktion, Fog für regionale Koordination und Cloud für Langzeitarchiv, Training und Auswertung über längere Zeiträume. Genau diese Aufteilung macht Netzwerke belastbar, ohne sie unnötig kompliziert zu machen.