
Ein industrielles IoT-System ist nur dann sinnvoll, wenn es Maschinen, Sensoren, Steuerungen und IT so verbindet, dass aus Rohdaten verwertbare Betriebsentscheidungen werden. Genau darum geht es hier: um den Aufbau solcher Systeme, um die Use Cases mit dem schnellsten Nutzen und um die Sicherheitsfragen, die ich in deutschen Produktionsumgebungen früh kläre. Wer Connectivity, Datenfluss und Betrieb zusammen denkt, vermeidet die typischen Pilotprojekte ohne Anschluss an den Alltag.
Die wichtigsten Punkte auf einen Blick
- Sensoren allein schaffen noch keinen Mehrwert, erst Alarmierung, Wartung und Auswertung machen daraus einen Prozessgewinn.
- OPC UA und MQTT ergänzen sich in der Praxis oft besser, als dass sie gegeneinander stehen.
- Die schnellsten Use Cases sind Zustandsüberwachung, Energieanalyse, Qualität und Rückverfolgbarkeit.
- In Bestandsanlagen entscheidet Brownfield-Tauglichkeit mehr als die perfekte Greenfield-Architektur.
- Security, Identität und Updatefähigkeit gehören vor den ersten Rollout, nicht danach.
Was industrielle IoT-systeme in der produktion leisten
Ich trenne industrielle IoT-Lösungen immer in drei Ebenen: erfassen, interpretieren, auslösen. Ein Temperatursensor ist für sich genommen nur ein Messpunkt; erst wenn die Daten mit Wartung, Qualität oder Energieverbrauch verbunden werden, entsteht ein echter Nutzen. Genau das ist der Unterschied zwischen einer hübschen Visualisierung und einem System, das im Alltag wirklich hilft.Das BSI beschreibt OT als die Ebene, die physische Geräte, Prozesse und Ereignisse in Anlagen überwacht und steuert. Darum reicht es nicht, die IT-Seite einzubinden und die Werkhalle als "nur noch ein weiteres Netzwerk" zu behandeln. Maschinen sprechen anders, reagieren anders und haben oft ganz andere Verfügbarkeitsanforderungen als klassische Büro-IT.
In der Praxis suche ich deshalb zuerst nach einem klaren Betriebsziel: weniger ungeplante Stillstände, weniger Ausschuss, niedrigere Energiekosten oder bessere Rückverfolgbarkeit. Erst danach entscheide ich, welche Sensorik, welche Verbindungsart und welche Analyseebene wirklich sinnvoll sind. Daraus ergibt sich automatisch der nächste Schritt, nämlich die Architektur.
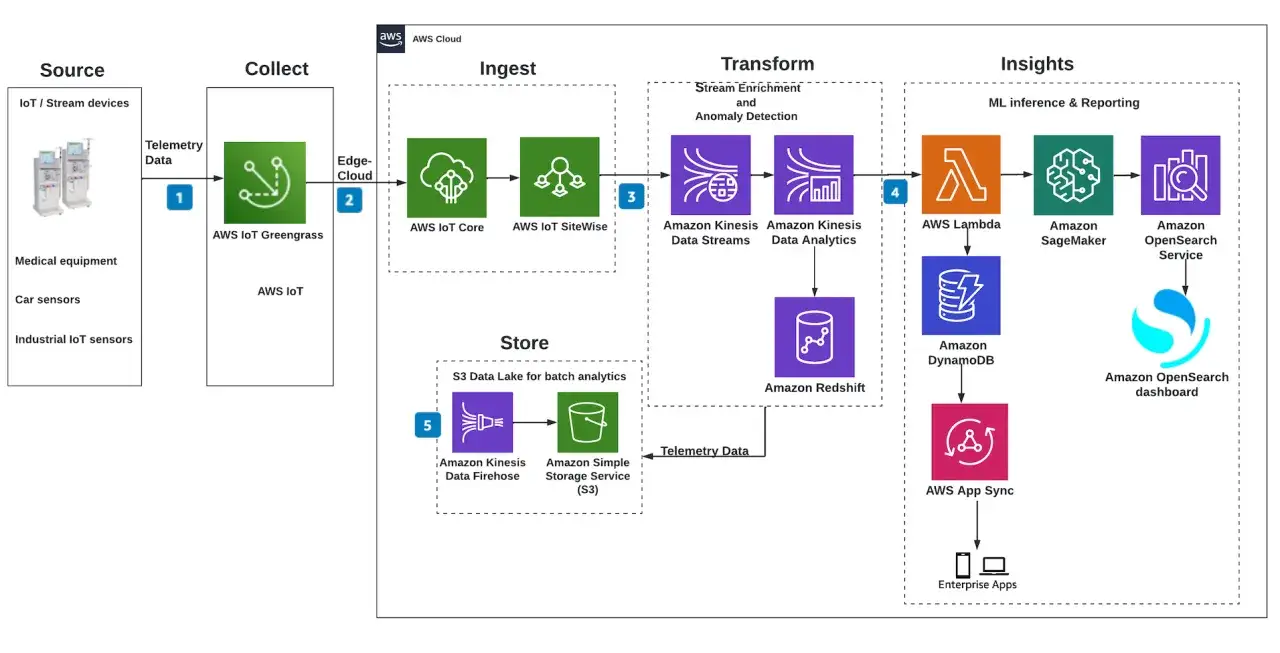
Aus welchen bausteinen eine robuste architektur besteht
Ein belastbares System entsteht nicht durch möglichst viele Geräte, sondern durch saubere Rollen. Ich plane deshalb immer von unten nach oben und frage mich bei jeder Ebene, was lokal bleiben muss, was gepuffert werden kann und was überhaupt in die Cloud gehört.
| Baustein | Aufgabe | Worauf ich achte |
|---|---|---|
| Sensoren und Aktoren | Messen und ausführen | Robustheit, Kalibrierung, Temperaturbereich, Wartbarkeit |
| PLC und Edge-Gateway | Vorverarbeiten, puffern, Protokolle übersetzen | Lokale Logik, Ausfallsicherheit, Zeitstempel, Store-and-forward |
| Netzwerk | Daten transportieren | Segmentierung, Redundanz, Latenz, saubere Adressierung |
| Datenplattform | Speichern, visualisieren, analysieren | Historie, APIs, Rollenmodell, Datenhoheit |
| Sicherheitslayer | Identität, Rechte, Protokollierung | Zertifikate, MFA, Logging, Rollentrennung |
Für die Zeitkritik gilt eine einfache Regel, die ich in Projekten immer wieder bestätigt sehe: Alles im Millisekundenbereich bleibt lokal oder am Edge. Zustandsdaten mit Sekunden- oder Minutenrhythmus können über Gateways in eine Plattform laufen, und Reporting hat noch mehr Luft. Nur weil alles vernetzt ist, muss nicht alles zentral verarbeitet werden.
Der typische Fehler im Brownfield ist ein überladenes Zielbild. Wer Bestandsanlagen in Deutschland modernisiert, braucht selten den perfekten Neubau-Stack, sondern eine Architektur, die bestehende PLCs, alte Sensorik und neue Datendienste vernünftig zusammenführt. Wenn diese Schichten sauber getrennt sind, lässt sich der erste Mehrwert viel einfacher isolieren.
Wo der nutzen im betrieb am schnellsten sichtbar wird
Die schnellsten Projekte sind selten die spektakulärsten. Ich setze häufig mit einer Linie oder einer Maschine an, die entweder viel Stillstand produziert oder viel Energie zieht, weil dort der Nutzen am schnellsten messbar ist. Das ist meist nüchterner als ein großes Innovationsnarrativ, aber deutlich ehrlicher.
| Use case | Typische Daten | Warum er schnell Nutzen bringt |
|---|---|---|
| Zustandsüberwachung | Vibration, Temperatur, Stromaufnahme | Auffälligkeiten werden früh sichtbar, bevor eine Störung teuer wird |
| Energiemonitoring | Lastprofile, Spitzenlasten, Druckluftverbrauch | Kosten und Verluste werden messbar statt vermutet |
| Qualitätssicherung | Prozesskurven, Grenzwerte, Zyklusdaten | Ausschuss und Nacharbeit lassen sich konkreter eingrenzen |
| Rückverfolgbarkeit | Chargen, Zeitstempel, Maschinenstatus | Audits, Reklamationen und Kundenanforderungen werden einfacher |
| Remote Service | Alarme, Logs, Firmwarestände | Serviceeinsätze werden schneller und oft seltener notwendig |
Ich mag an diesen Anwendungsfällen vor allem, dass sie sich sauber operationalisieren lassen. Zustandsüberwachung bringt etwas, wenn ein Alarm in einen Wartungsprozess mündet. Energiemonitoring bringt etwas, wenn Lastspitzen gegen reale Produktionsfenster abgeglichen werden. Qualität bringt etwas, wenn der Datensatz vollständig genug ist, um Ursachen einzugrenzen, statt nur Symptome zu zeigen.
Gerade in deutschen Werken, in denen Brownfield oft die Norm ist, rechne ich nicht mit einem großen Sprung, sondern mit vielen kleinen, gut begründbaren Verbesserungen. Das ist kein Nachteil. Es ist meist der einzige Weg, der sich im Betrieb wirklich durchhält. Damit sind die Use Cases klar, jetzt kommt die Umsetzung.
Wie ich ein projekt ohne teure schleifen aufsetze
Ein realistischer Pilot braucht Wochen bis wenige Monate, nicht nur ein paar Tage. Wenn ich in drei Tagen ein Dashboard habe, ist das noch kein belastbares Betriebssystem. Darum starte ich nicht mit möglichst vielen Maschinen, sondern mit einem klar abgegrenzten Bereich und einem einzigen messbaren Ziel.
- Ziel und KPI festlegen. Ich definiere zuerst, was am Ende besser sein soll, zum Beispiel weniger Stillstand, weniger Energieverbrauch oder schnellere Störungsanalyse.
- Eine Anlage oder Linie auswählen. Ein sauberer Pilot ist klein genug, um kontrollierbar zu bleiben, aber groß genug, um echte Daten zu liefern.
- Datenzugang und Zuständigkeiten klären. Wer liest, wer schreibt, wer darf konfigurieren und wer reagiert auf Alarme?
- Pilot in den Betriebsprozess einbinden. Ein gutes IoT-System endet nicht im Dashboard, sondern im Wartungs-, Qualitäts- oder Serviceablauf.
- Nach dem Nachweis standardisieren. Erst wenn der Nutzen belegt ist, skaliere ich auf weitere Anlagen, damit aus einem Versuch kein Einzelfall bleibt.
Die häufigsten Fehler sind ziemlich vorhersehbar: zu viele Geräte, zu viele KPIs, zu wenig Verantwortung. Ebenfalls problematisch ist der Drang, sofort alles in die Cloud zu verlagern. In vielen Anlagen ist lokale Vorverarbeitung stabiler, günstiger und betrieblich robuster. Ab hier entscheidet Sicherheit darüber, ob der Betrieb später ruhig bleibt.
Sicherheit, lebenszyklus und zuständigkeiten von anfang an mitdenken
Das BSI behandelt OT als die Umgebung, in der physische Prozesse geschützt werden müssen, nicht nur Server und Benutzerkonten. Genau deshalb müssen Segmentierung, Zugriffsrechte und Patchfenster an den Maschinenbetrieb angepasst werden. Was in einer Büro-IT schnell geht, kann an einer laufenden Linie sofort ein Produktionsrisiko werden.
Die IEC weist darauf hin, dass IACS-Lebenszyklen 20 Jahre überschreiten können; die jüngere 62443-1-6 ergänzt den Rahmen ausdrücklich für IIoT. Für mich ist das die beste Erinnerung daran, dass man Altanlagen nicht wie frische IT-Projekte behandelt. Wer im Brownfield arbeitet, braucht nicht nur Security-Tools, sondern auch kompensierende Maßnahmen für Geräte, die sich nicht einfach modernisieren lassen.
- Ich erfasse zuerst alle Assets, inklusive Sensoren, Gateways, PLCs und Fernzugänge.
- Ich trenne Netze so, dass nicht jedes Gerät direkt mit jedem anderen spricht.
- Ich vergebe eindeutige Identitäten statt generischer Standardzugänge.
- Ich teste Backups und Wiederherstellung, nicht nur deren Existenz.
- Ich plane Update- und Vulnerability-Prozesse so, dass der Betrieb nicht bei jedem Patch ins Risiko läuft.
Besonders wichtig ist mir der Umgang mit Remote-Zugriff. Wenn ein Servicetechniker oder ein Hersteller aus der Ferne auf die Anlage zugreifen muss, braucht es eine klare technische und organisatorische Kette, sonst wird Komfort schnell zum Einfallstor. Wenn Security und Lebenszyklus klar sind, kann ich über Standards sprechen, ohne ein neues Datensilo zu bauen.
Warum sich in deutschland bestimmte standards durchgesetzt haben
In deutschen Produktionsumgebungen geht es oft weniger um den nächsten Hype als um Interoperabilität zwischen Maschinenbauern, Anlagenbau, Automatisierung und IT. Ich sehe deshalb vor allem drei Bausteine immer wieder: OPC UA, MQTT und die Verwaltungsschale, also die AAS. Sie lösen nicht dasselbe Problem, und genau das macht sie zusammen so nützlich.
| Standard oder Konzept | Rolle | Wann ich ihn einsetze |
|---|---|---|
| OPC UA | Semantischer Austausch am Shopfloor | Wenn Maschinen, Steuerungen und IT denselben Datenraum verstehen sollen |
| MQTT | Leichtgewichtiger Event-Transport | Wenn viele kleine Nachrichten vom Edge in eine Plattform laufen sollen |
| Verwaltungsschale AAS | Struktur und digitale Beschreibung eines Assets | Wenn Daten verschiedener Lieferanten und Systeme interoperabel werden sollen |
OPC UA ist stark, wenn Maschinen nicht nur Daten, sondern auch Bedeutung senden sollen. MQTT ist praktisch, wenn viele Ereignisse schlank weitergeleitet werden müssen, etwa für Telemetrie oder Ereignisströme. Die AAS ist keine Alternative zum Protokoll, sondern die Beschreibungsschicht darüber. Genau diese Trennung hilft in heterogenen Anlagen, weil nicht jede Maschine neu erfunden werden muss, nur damit sie mit der IT sprechen kann.
Die technische Konsequenz ist klar: Ich kombiniere lieber wenige, gut verstandene Standards als einen überladenen Werkzeugkasten. In der deutschen Industrie-4.0-Landschaft hat sich genau diese Haltung bewährt, weil sie Integration vereinfacht und spätere Erweiterungen nicht blockiert. Am Ende entscheidet aber nicht die Anzahl der Standards, sondern ob sie im Betrieb zusammenspielen.
Was einen belastbaren rollouts von einem teuren pilotprojekt trennt
Wenn ich ein Projekt heute bewerte, stelle ich drei Fragen. Kann die Anlage bei Netzproblemen weiterarbeiten? Ist klar, wer Daten, Firmware und Alarme verantwortet? Und lässt sich der Nutzen nach einigen Wochen oder Monaten im Alltag wirklich messen? Wenn eine dieser Fragen offen bleibt, ist das Projekt noch nicht reif für die Fläche.
- Ein guter Rollout beginnt mit einer Anlage, nicht mit einer ganzen Fabrik.
- Ein guter Rollout kennt seinen Datenbesitzer, seinen Betreiber und seinen Serviceweg.
- Ein guter Rollout hat einen Fallback, wenn die Verbindung oder die Plattform ausfällt.
- Ein guter Rollout wird an einem KPI gemessen, den der Betrieb selbst ernst nimmt.
Genau dort liegt für mich der Unterschied zwischen einer schönen Demo und einer belastbaren industriellen Infrastruktur. Wenn Daten, Zuständigkeiten, Security und Standards zusammenpassen, wird aus vernetzter Sensorik ein System, das im Werk, in der Wartung und in der Leitwarte wirklich trägt.