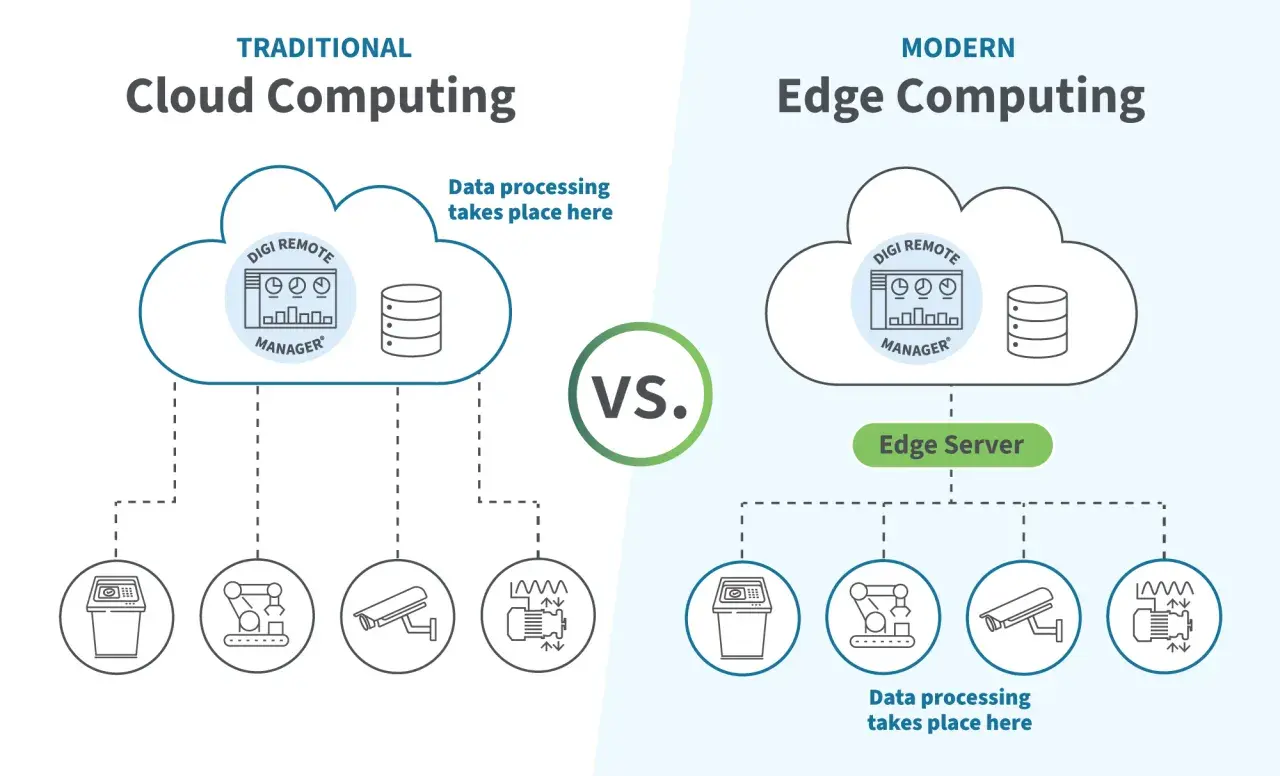
IoT-Systeme entfalten ihren Wert erst dann richtig, wenn aus rohen Sensordaten schnell verwertbare Entscheidungen werden. Genau hier setzt der Ansatz des intelligent edge an: Daten werden näher an der Quelle verarbeitet, gefiltert und nur dann weitergeleitet, wenn es technisch und wirtschaftlich Sinn ergibt. Das senkt Reaktionszeiten, entlastet Netze und macht vernetzte Anlagen robuster, besonders dort, wo Verbindungen schwanken oder teuer sind.
Für Infrastruktur, Telekommunikation und verteilte Systeme ist das keine abstrakte Architekturfrage, sondern eine praktische Weichenstellung. Ich zeige hier, wie die Architektur funktioniert, welche Bausteine sie braucht, wo sie in IoT-Umgebungen wirklich hilft und welche Grenzen man realistisch einplanen sollte.
Die wichtigsten Punkte auf einen Blick
- Edge-Verarbeitung bringt Rechenleistung näher an Sensoren, Maschinen und Gateways und reduziert so Latenz und Netzlast.
- Der größte Nutzen entsteht bei zeitkritischen Anwendungen, hohem Datenaufkommen und unzuverlässiger Konnektivität.
- In IoT-Systemen ist die beste Lösung meist hybrid: lokal entscheiden, zentral koordinieren und auswerten.
- Ohne sauberes Update-Management, Monitoring und Security wird Edge schnell komplizierter statt besser.
- Gerade in verteilten Infrastrukturen, auf Inseln oder an abgelegenen Standorten kann der Ansatz den Unterschied zwischen „läuft“ und „steht“ machen.
Wie die Datenverarbeitung näher an die Quelle rückt
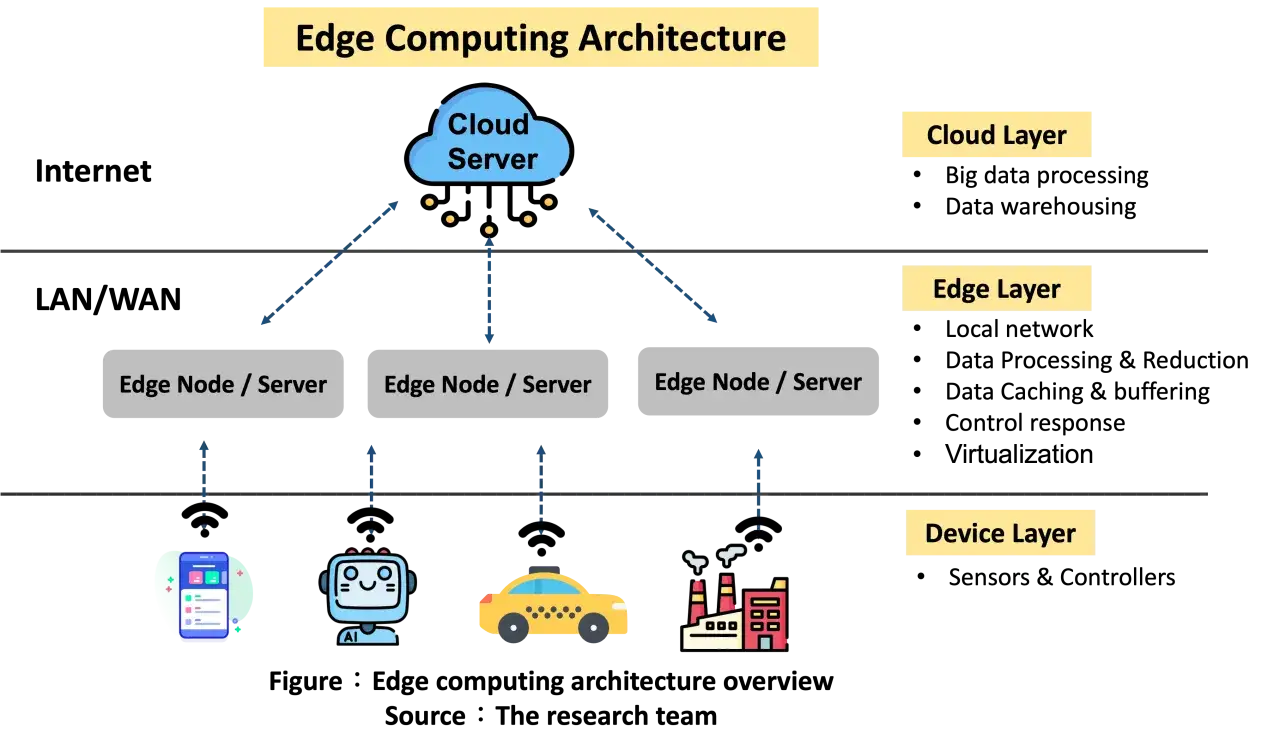
Ich denke bei solchen Architekturen gern in vier Ebenen: Gerät, lokales Gateway, Edge-Knoten und Cloud. Ein Sensor misst Temperatur, Vibration, Bilddaten oder Stromverbrauch. Das Gateway prüft zunächst, ob die Daten plausibel sind, filtert Ausreißer und verdichtet Messreihen. Der Edge-Knoten übernimmt dann die eigentliche Voranalyse, etwa Mustererkennung, Alarmregeln oder eine lokale KI-Inferenz. Nur relevante Ereignisse, Zustände oder verdichtete Datensätze wandern anschließend in die Cloud.
Der praktische Unterschied ist groß: Statt jedes Rohsignal durch ein zentrales Rechenzentrum zu schicken, werden Entscheidungen dort getroffen, wo sie entstehen. Je näher die Analyse an der Quelle liegt, desto schneller und unabhängiger kann das System reagieren. Für IoT bedeutet das vor allem weniger Wartezeit zwischen Messung und Aktion.
- Erfassung durch Sensoren, Aktoren oder Kameras.
- Vorverarbeitung auf dem Gateway, etwa Bereinigung, Filterung oder Aggregation.
- Lokale Auswertung auf einem Edge-Server, Mini-Industrie-PC oder Embedded-System.
- Weitergabe nur relevanter Ereignisse, Metadaten oder Batch-Daten in zentrale Systeme.
Genau diese Aufteilung ist der Kern moderner IoT-Architekturen. Und sobald man sie verstanden hat, wird klar, warum sich die Frage nach dem Nutzen so direkt an Latenz, Bandbreite und Ausfallsicherheit knüpft.
Warum IoT-Systeme davon messbar profitieren
Die Vorteile sind nicht theoretisch, sondern im Betrieb gut spürbar. Wer Tausende Sensoren, Kameras oder Maschinenkomponenten betreibt, stößt mit rein zentraler Verarbeitung schnell an Grenzen. Ich sehe in Projekten immer wieder dieselben drei Engpässe: zu viel Datenverkehr, zu langsame Reaktion und zu hohe Abhängigkeit von einer stabilen Verbindung.
| Kriterium | Cloud-zentriert | Edge-nah | Praktischer Effekt |
|---|---|---|---|
| Latenz | Abhängig von WAN und Backhaul, oft deutlich höher | Reaktion vor Ort, häufig im Bereich weniger bis niedriger zweistelliger Millisekunden | Geeignet für Alarme, Steuerungen und Sicherheitsfunktionen |
| Bandbreite | Rohdaten werden häufig vollständig übertragen | Nur Ereignisse, Metadaten oder komprimierte Daten wandern weiter | Weniger Netzlast und geringere Übertragungskosten |
| Ausfallsicherheit | Stark von externer Verbindung abhängig | Lokale Grundfunktionen bleiben auch bei Verbindungsproblemen aktiv | Mehr Autonomie an abgelegenen oder kritischen Standorten |
| Datenschutz | Mehr Daten verlassen den Standort | Verarbeitung bleibt näher an der Erhebung | Weniger Datenbewegung, oft einfacher mit Compliance zu verbinden |
| Betrieb | Zentral einfacher zu standardisieren | Verteilte Verwaltung braucht Disziplin | Mehr Aufwand, aber auch mehr lokale Kontrolle |
Die Cloud verschwindet dadurch nicht. Sie bleibt der richtige Ort für Langzeitspeicherung, Flottenanalyse, Modelltraining und standortübergreifende Auswertungen. Edge ersetzt die Cloud nicht, sondern nimmt ihr die Aufgaben ab, die lokal schneller oder robuster erledigt werden müssen. Genau deshalb ist der hybride Ansatz in IoT-Systemen meist der vernünftigste.
Wo die Architektur besonders gut passt
Besonders stark ist die lokale Verarbeitung dort, wo Daten viel Volumen haben, Reaktionen sofort passieren müssen oder Verbindungen nicht durchgehend zuverlässig sind. Das ist in Industrieumgebungen so, aber genauso in Infrastrukturprojekten, Versorgungssystemen und verteilten Netzen. Gerade in Ländern mit Inseln, langen Leitungswegen oder einzelnen entlegenen Standorten wird das schnell relevant.
- Videoanalyse an kritischen Punkten wie Häfen, Zufahrten oder Lagerflächen: Das System erkennt Ereignisse vor Ort und sendet nicht dauernd Rohvideo in die Cloud.
- Predictive Maintenance an Pumpen, Generatoren oder Klimaanlagen: Schwingungs- und Temperaturdaten werden lokal bewertet, damit Ausfälle früher auffallen.
- Smart Metering und Netzüberwachung: Lokale Knoten können Lastspitzen, Fehlerzustände oder Manipulationsmuster schneller erkennen als eine rein zentrale Auswertung.
- Remote-Standorte mit schwacher Konnektivität: Kleine Versorgungsstationen, Außenposten oder Messpunkte bleiben auch bei instabilen Links funktionsfähig.
- Umwelt- und Küstenmonitoring: Sensoren an entfernten Messpunkten schicken nur verdichtete Ereignisse statt dauernd volle Datenströme.
Der gemeinsame Nenner ist immer derselbe: Je teurer, langsamer oder störanfälliger die Übertragung, desto wertvoller wird lokale Intelligenz. Im nächsten Schritt lohnt sich deshalb ein genauer Blick auf die Bausteine, die ein belastbares Setup überhaupt erst möglich machen.
Welche Bausteine ein belastbares Setup braucht
Ein funktionierendes Setup besteht nicht nur aus „ein bisschen Rechenleistung am Rand“. In der Praxis braucht man eine saubere Staffelung von Aufgaben, Zuständigkeiten und Updatewegen. Wenn diese Schichten unsauber vermischt werden, wird das System schwer wartbar und teuer im Betrieb.
Geräte und Sensoren
Die unterste Ebene liefert Messwerte, Bilder, Zustände oder Telemetriedaten. Hier entscheidet sich bereits, wie viel Vorverarbeitung überhaupt möglich ist. Gute Sensorik ist nicht nur präzise, sondern auch stabil kalibrierbar und energieeffizient.
Gateway und Vorfilterung
Das Gateway bündelt Signale aus mehreren Geräten, prüft Protokolle, normalisiert Daten und wirft offensichtliche Fehler aus. Das ist oft der erste Ort, an dem aus rohen Werten strukturierte Informationen werden. Für einfache IoT-Systeme kann diese Ebene schon reichen.
Lokaler Rechenknoten
Hier laufen Regeln, Analytik und gegebenenfalls KI-Modelle. Das kann ein Industrie-PC, ein kompakter Server oder ein spezialisierter Embedded-Knoten sein. Wichtig ist nicht die maximale Leistung, sondern die richtige Leistung am richtigen Ort.
Lesen Sie auch: IoT-Sicherheit - Schwachstellen, Schutz & Regulierung 2026
Orchestrierung, Sicherheit und Updates
Je verteilter das System, desto wichtiger wird die Betriebsseite. Container, Signaturen, Rollenmodelle, Gerätezertifikate und sichere Fernupdates sind keine Nebensache. Ich würde ohne klares Patch- und Rollback-Konzept kein einziges größeres Edge-Projekt in Betrieb nehmen.
Diese Bausteine klingen technisch, sind aber in Wahrheit vor allem ein Betriebsmodell. Und genau dort liegen auch die Grenzen, die man nüchtern sehen sollte, statt sie wegzuerzählen.
Wo Edge nicht automatisch besser ist
So nützlich lokale Verarbeitung auch ist, sie ist kein Allheilmittel. Der häufigste Fehler ist, alles „smart“ machen zu wollen, obwohl ein Teil der Daten auch gut zentral verarbeitet werden könnte. Dann baut man Komplexität, ohne echten Mehrwert zu gewinnen.
| Typische Grenze | Was dann schiefgeht | Was besser hilft |
|---|---|---|
| Sehr geringe Datenmenge | Der lokale Betrieb lohnt sich kaum | Einfaches Cloud- oder Gateway-Modell |
| Schwere KI-Modelle | Zu hohe Last für kleine Edge-Geräte | Modellkompression, schlankere Inferenz oder Hybridbetrieb |
| Viele Standorte | Wartung und Updates werden unübersichtlich | Zentrales Device-Management und klare Standards |
| Schwache Energieversorgung | Edge-Hardware wird zum Stabilitätsrisiko | Robuste, stromsparende Geräte mit Pufferkonzept |
| Unklare Verantwortlichkeiten | Niemand fühlt sich für Betrieb, Sicherheit oder Datenqualität zuständig | Saubere Rollen und Betriebsprozesse vor dem Rollout |
Mein Maßstab ist einfach: Wenn ein Use Case nur Daten sammelt, aber keine lokale Entscheidung braucht, ist eine schwere Edge-Architektur meist unnötig. Wenn aber Ausfälle teuer sind, Reaktionszeit zählt oder die Verbindung unzuverlässig ist, kippt die Rechnung schnell zugunsten einer lokalen Verarbeitung.
Wie ich ein IoT-Projekt dafür aufsetze
Ich starte nie mit Hardware, sondern mit der Frage, welche Entscheidungen wirklich vor Ort fallen müssen. Das klingt simpel, verhindert aber viele Fehlplanungen. Erst wenn klar ist, welche Aufgaben lokal bleiben und welche in die Cloud gehören, lässt sich die technische Architektur sauber zuschneiden.
- Use Case scharf abgrenzen: Muss das System in Sekunden, Millisekunden oder nur irgendwann reagieren?
- Datenfluss aufteilen: Welche Rohdaten bleiben lokal, welche werden verdichtet, welche wandern zentral weiter?
- Verbindung realistisch planen: Wie verhält sich das System bei Ausfällen, hohem Jitter oder langsamer Rückkanal-Anbindung?
- Hardware nach Betriebsprofil auswählen: Leistungsaufnahme, Temperaturbereich, Speicher und Reserve zählen oft mehr als Marketingwerte.
- Update- und Monitoringpfad festlegen: Ohne sauberes Fernmanagement wird der Betrieb über Monate unnötig teuer.
- Fallback definieren: Das System muss auch dann sinnvoll weiterlaufen, wenn ein Teil der Infrastruktur kurzzeitig ausfällt.
In der Praxis hat sich für mich ein Prinzip bewährt: lokal entscheiden, zentral lernen. Das heißt, kritische Reaktionen bleiben nah am Gerät, während Analyse, Optimierung und Langzeitarchivierung zentral laufen. So bleibt das System schnell, aber nicht überladen.
Worauf ich 2026 bei neuen Installationen zuerst achte
2026 ist der Markt reif genug, um sich nicht mehr von der reinen Schlagwortlogik leiten zu lassen. Ich schaue zuerst darauf, ob ein Projekt echte lokale Intelligenz braucht oder nur einen gut angebundenen Sensor mit sauberer Cloud-Anbindung. Dieser Unterschied spart oft mehr Geld als jede spätere Optimierung.
- Relevanz für Echtzeit: Gibt es Entscheidungen, die nicht auf eine zentrale Runde warten dürfen?
- Konnektivitätsqualität: Ist die Verbindung stabil genug, um auf permanente Cloud-Nutzung zu setzen?
- Wartbarkeit: Kann das Team Hunderte Geräte sicher aktualisieren, überwachen und absichern?
- Datenvolumen: Entstehen viele Rohdaten, die lokal gefiltert oder verdichtet werden sollten?
- Betriebsrealität: Passt die Lösung zur Energieversorgung, zur physischen Umgebung und zur lokalen IT-Organisation?
Wenn diese Punkte sauber beantwortet sind, wird aus einer schicken Architektur ein belastbares System. Und genau das ist der eigentliche Mehrwert: nicht möglichst viel Rechenleistung am Rand, sondern die richtige Entscheidung an der richtigen Stelle.