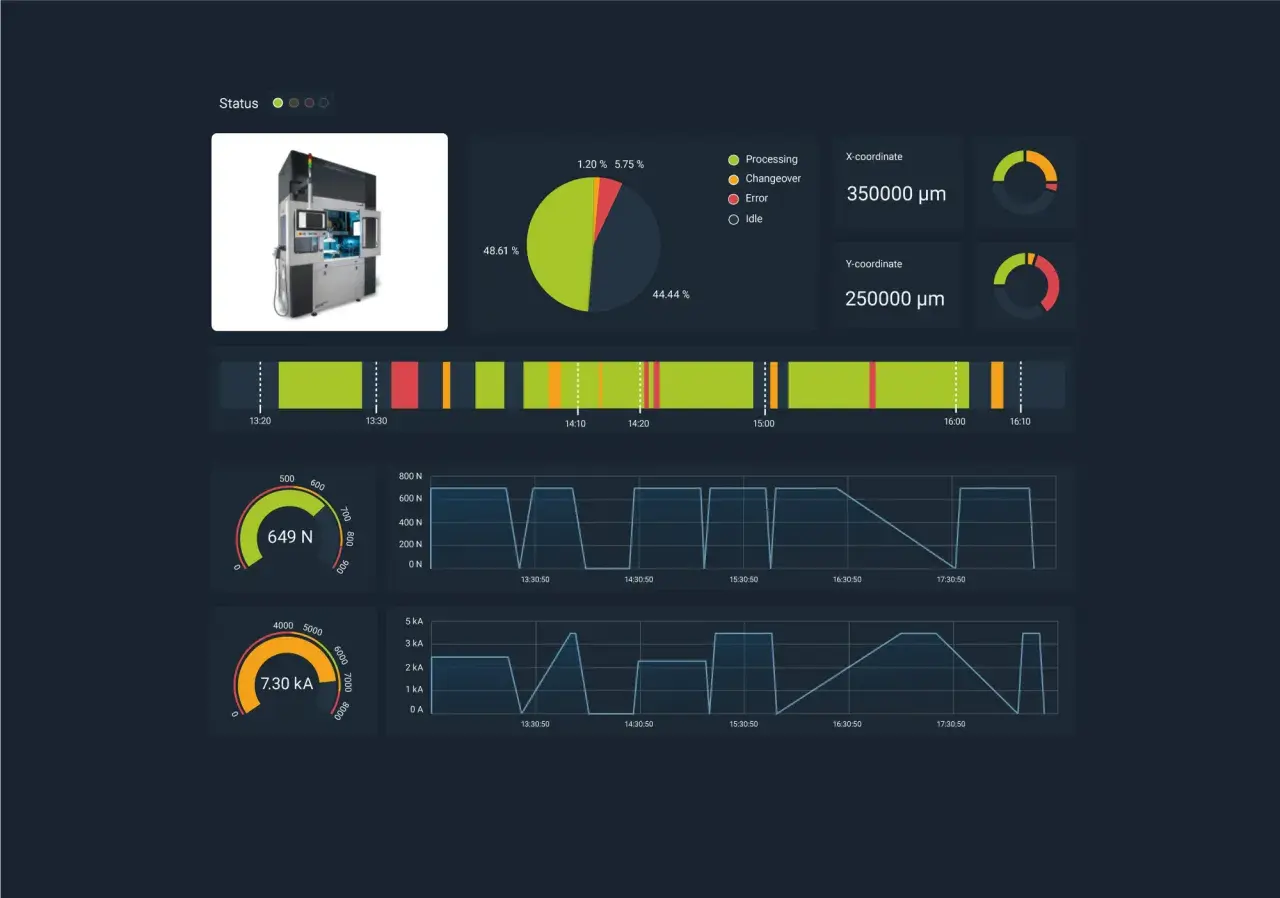
Vorausschauende Wartung entfaltet ihren Nutzen erst dann, wenn sie Störungen nicht nur meldet, sondern ihre Ursache früh genug sichtbar macht. Der Ansatz iot predictive maintenance verbindet Sensorik, Datenanalyse und Instandhaltung so, dass Teams nicht mehr auf den nächsten Ausfall warten müssen, sondern Eingriffe planbar machen. In der Praxis ist das kein reines KI-Thema, sondern vor allem eine Frage von sauberen Zustandsdaten, verlässlicher Konnektivität und klaren Wartungsprozessen.
Die wichtigsten Punkte auf einen Blick
- Der eigentliche Wert liegt nicht in der Prognose allein, sondern in der Frage, welche Wartungsentscheidung daraus folgt.
- Vibration, Temperatur, Stromaufnahme, Druck und Durchfluss liefern in vielen Anlagen die zuverlässigsten Frühindikatoren.
- Ohne Edge-Pufferung, saubere Datenstrecke und CMMS-Anbindung bleibt eine gute Vorhersage oft nur ein Dashboard.
- Wirtschaftlich sinnvoll ist der Ansatz vor allem bei kritischen, teuren oder schwer zugänglichen Anlagen.
- Der häufigste Fehler ist nicht das Modell, sondern fehlende Datenqualität und unklare Reaktion auf Alarme.
Was vorausschauende Wartung mit IoT wirklich leistet
Ich halte es für wichtig, den Begriff zuerst sauber einzuordnen: Es geht nicht darum, den exakten Ausfalltag einer Maschine zu erraten. Viel nützlicher ist die Frage, ob sich das Risiko für einen Defekt gerade erhöht, welche Komponente betroffen ist und wie viel Zeit noch bleibt, um sicher zu reagieren. Genau hier unterscheidet sich zustandsbasierte Instandhaltung von klassischer, zeitgesteuerter Wartung.
Die Logik ist einfach, aber die Wirkung ist groß. Statt alle 6 Monate blind ein Lager zu tauschen, prüft das System laufend, ob Vibration, Temperatur oder Stromaufnahme von einem stabilen Normalzustand abweichen. Aus diesen Abweichungen entstehen Anomalien, Warnstufen oder eine Schätzung der verbleibenden Nutzungsdauer, also die bekannte RUL (Remaining Useful Life), also die geschätzte Restlebensdauer eines Bauteils.
Ich sehe in Projekten immer wieder denselben Punkt: Wenn das System nur Zahlen zeigt, aber keine Wartungsentscheidung auslöst, verpufft der Nutzen. Erst wenn eine Meldung direkt in einen Arbeitsauftrag, eine Ersatzteilprüfung oder eine geplante Stillstandsphase führt, wird aus Monitoring echte Instandhaltungsintelligenz. Damit stellt sich sofort die nächste Frage: Welche Signale sind überhaupt belastbar genug, um so etwas zu tragen?
Welche Sensoren und Signale die Vorhersage tragen
Nicht jede Anlage braucht denselben Sensor-Mix. Ich würde immer vom Fehlerbild ausgehen: Welche Bauteile fallen typischerweise aus, wie kündigt sich das an und welche Messgröße reagiert zuerst? In vielen industriellen Umgebungen reichen schon wenige gut platzierte Sensoren, wenn sie sauber kalibriert und sinnvoll ausgewertet werden.
| Sensor oder Signal | Was es typischerweise verrät | Typische Messlogik | Worauf ich besonders achte |
|---|---|---|---|
| Vibration | Unwucht, Fluchtungsfehler, Lagerverschleiß, mechanische Lockerung | Trendwerte im Sekundentakt, Rohdaten bei Bedarf hochfrequent | Saubere Montage und ein stabiler Referenzzustand |
| Temperatur | Überhitzung, Reibung, Kühlprobleme, elektrische Lastspitzen | Alle 10 bis 60 Sekunden oder kontinuierlich | Umgebungseinfluss von eigentlichem Anlagenverhalten trennen |
| Stromaufnahme und Leistung | Mechanische Last, Blockaden, Reibung, ungewöhnliche Lastwechsel | Typisch alle 1 bis 10 Sekunden als Trend | Nur zusammen mit Betriebszustand und Lastprofil interpretieren |
| Druck und Durchfluss | Leckagen, Verstopfungen, Pumpenprobleme, Ventilfehler | Je nach Prozess zwischen 1 und 30 Sekunden | Kalibrierung und Prozessbezug sind hier entscheidend |
| Akustik oder Ultraschall | Leckagen, frühe Reibprobleme, ungewöhnliche Geräuschmuster | Ereignisorientiert oder dauerhaft bei kritischen Punkten | Umgebungsgeräusche und Reflexionen nicht unterschätzen |
Für viele Anlagen ist es sinnvoll, zuerst 1 bis 3 kritische Assetklassen zu wählen und dort 8 bis 12 Wochen saubere Normaldaten zu sammeln. Wenn Ausfälle selten sind, ist Anomalieerkennung oft praktikabler als ein klassisches Klassifikationsmodell, das für jede Fehlerart bereits viele Beispiele braucht. Genau an diesem Punkt trennt sich die Theorie von einem nutzbaren System, und deshalb lohnt sich der Blick auf die Datenkette vom Sensor bis zur Entscheidung.

Wie aus Daten eine Wartungsentscheidung wird
Ein robustes System besteht nicht nur aus Sensoren, sondern aus einer ganzen Kette: Sensor, Gateway, Datenplattform, Modell und Wartungsprozess. Fraunhofer EMFT beschreibt in aktuellen Projekten genau dieses Problemfeld sehr treffend: In realen Produktionsumgebungen sind die Daten meist heterogen, unvollständig und technisch alles andere als ideal. Darum funktioniert der Weg zur Vorhersage nur, wenn jede Stufe bewusst gestaltet wird.
Daten lokal vorverdichten
Ich würde Rohdaten nicht blind in die Cloud schicken. Ein Edge-Gateway kann schon vor Ort filtern, glätten, komprimieren und bei Verbindungsabbrüchen puffern. Gerade bei sensiblen Produktionsanlagen oder verteilten Standorten ist das oft die sauberste Lösung, weil nur relevante Ereignisse weitergeleitet werden und der Rest lokal bleibt.
Modelle passend zur Datenlage wählen
Wenn es bereits belastbare Historien gibt, kann ein überwachtes Modell sinnvoll sein, das bekannte Fehlerarten erkennt. Wenn die Fehler selten oder schlecht dokumentiert sind, ist eine Anomalieerkennung meist realistischer. Ich halte es für einen typischen Anfängerfehler, sofort das komplexeste Modell zu verlangen, obwohl die Datenbasis dafür gar nicht reicht.
Lesen Sie auch: MQTT vs. WebSocket im IoT - Was ist besser und warum?
Alarme in den Wartungsprozess zurückspielen
Der eigentliche Gewinn entsteht erst, wenn ein Alarm in ein CMMS oder ein anderes Instandhaltungsmanagement-System zurückfließt. Dann entsteht aus einer technischen Auffälligkeit ein Arbeitsauftrag, eine Ersatzteilprüfung oder eine geplante Inspektion. Ohne diesen Rückkanal wird aus guter Diagnose nur zusätzliche Bildschirmarbeit.
Wer diese Kette sauber aufsetzt, hat schon viel gewonnen. Der nächste Engpass entsteht häufig nicht am Sensor, sondern in der Verbindung zwischen Anlage, Netz und Plattform.
Welche Konnektivität im Feld wirklich taugt
Gerade bei IoT-Systemen entscheidet die Verbindung mit darüber, ob eine gute Vorhersage in der Praxis ankommt. In Hallen, Außenanlagen oder dezentralen Standorten braucht man nicht nur Bandbreite, sondern auch Verfügbarkeit, Pufferung und ein gutes Verständnis dafür, welche Daten lokal bleiben können und welche sofort weiter müssen. Ich würde bei kritischen Anlagen immer so planen, dass Ausfälle der Leitung nicht automatisch den ganzen Prozess ausbremsen.
| Technik | Stärke | Grenze | Typischer Einsatz |
|---|---|---|---|
| Ethernet und Industrie-WLAN | Hohe Datenrate, gute Integration in Werkhallen | Verkabelungsaufwand, begrenzte Abdeckung | Maschinenparks, Produktionszellen, feste Anlagen |
| LTE und 5G | Mobil, weitreichend, gut für verteilte Standorte | Laufende Kosten, Indoor-Funk kann schwanken | Außenanlagen, Logistik, Energie- und Infrastrukturstandorte |
| NB-IoT und LoRaWAN | Energiearm, geeignet für seltene Messwerte | Geringe Bandbreite, nicht für hochfrequente Rohdaten | Zähler, Umweltmessung, abgelegene Sensorik |
| MQTT | Schlankes Telemetrieprotokoll, leicht skalierbar | Benötigt Broker und saubere Topic-Struktur | Sensor-zu-Plattform-Kommunikation |
| OPC UA | Sehr gut für strukturierte Maschinendaten aus der OT | Integration kann aufwendiger sein | Brownfield-Integration, SPS-nahe Datenquellen |
Mein praktischer Richtwert ist schlicht: Alarme müssen nicht millisekundengenau sein, aber die Rohdaten sollten lokal mindestens 24 Stunden, oft besser 72 Stunden, gepuffert werden können. So bleibt das System handlungsfähig, selbst wenn die Leitung kurzzeitig ausfällt. Wenn die Verbindung tragfähig ist, kommt die nächste Frage: Wann rechnet sich der Aufwand überhaupt?
Wann sich der Ansatz rechnet und wann nicht
Ich würde predictive Maintenance nie als Selbstzweck aufsetzen. Sie lohnt sich vor allem dort, wo Ausfallkosten hoch, Ersatzteile teuer, Zugänge schwierig oder Prozessunterbrechungen besonders schmerzhaft sind. Bei leicht austauschbaren, wenig kritischen Komponenten ist eine einfache präventive Wartung oft völlig ausreichend.
| Strategie | Vorteil | Nachteil | Geeignet für |
|---|---|---|---|
| Reaktive Wartung | Sehr geringer Startaufwand | Hohe Risiken durch ungeplante Stillstände | Nicht kritische, leicht austauschbare Assets |
| Präventive Wartung | Einfach planbar | Oft zu früh, oft zu spät, manchmal unnötig | Komponenten mit bekannten Verschleißintervallen |
| Zustandsbasierte Wartung | Reagiert auf reale Abnutzung | Benötigt gute Messdaten | Anlagen mit klaren Zustandsindikatoren |
| Vorausschauende Wartung | Beste Timing-Qualität bei der Intervention | Höchster Einführungsaufwand | Kritische, teure oder schwer zugängliche Anlagen |
Die drei Fragen, die ich in jedem Pilotprojekt zuerst kläre, sind erstaunlich simpel: Wie teuer ist eine Stunde Stillstand? Wie häufig treten die relevanten Fehler auf? Und kann man aus einem Alarm wirklich eine sinnvolle Aktion ableiten? Wenn eine dieser Antworten fehlt, ist der wirtschaftliche Fall schwach. Deshalb lohnt sich der Blick auf die typischen Fehler, bevor man zu viel Geld in die falsche Richtung schiebt.
Welche Fehler Projekte in der Praxis ausbremsen
Fraunhofer IESE weist in seiner Arbeit zu Predictive-Maintenance-Vorhaben regelmäßig auf zwei Bremser hin: schlechte Datenqualität und fehlendes Fachwissen. Genau das sehe ich in der Praxis auch am häufigsten. Es scheitert selten daran, dass der Sensor technisch nichts kann, sondern daran, dass das Projekt zu früh zu viel erwartet.
- Mit dem Modell anfangen statt mit dem Fehlerbild führt fast immer zu unklaren Ergebnissen.
- Sensoren falsch platzieren oder schlecht kalibrieren erzeugt Daten, die zwar hübsch aussehen, aber wenig aussagen.
- Zu wenig Normal- und Fehlersituationen machen das Training instabil oder unzuverlässig.
- Alarme ohne klare Reaktionskette erzeugen nur Alarmmüdigkeit im Team.
- Drift ignorieren ist gefährlich, weil sich Maschinen, Lasten und Umgebungen über die Zeit verändern.
- Security nach hinten schieben ist ein Fehler, sobald Sensoren und OT-Netze miteinander sprechen.
Ich würde zusätzlich auf ein oft unterschätztes Problem achten: Das Wartungsteam braucht Vertrauen in das System. Wenn drei von fünf Alarmen ins Leere laufen, wird das Tool nicht mehr ernst genommen, selbst wenn das Modell eigentlich solide ist. Deshalb muss die Einführung technisch und organisatorisch gleichzeitig geplant werden, nicht nacheinander. Daraus ergibt sich die nächste Frage: Wie sollte ein Start in Deutschland 2026 konkret aussehen?
Was ich für einen sauberen Start in Deutschland 2026 empfehlen würde
Für deutsche Unternehmen, vor allem im Mittelstand, ist der beste Einstieg meist nicht der Vollausbau, sondern ein gut gewählter Brownfield-Pilot. Ich würde mit Anlagen starten, die drei Eigenschaften haben: hoher Stillstandsschaden, klar erkennbare Verschleißmuster und eine halbwegs zugängliche Sensorik. Typische Kandidaten sind Pumpen, Kompressoren, Fördertechnik, Kühlaggregate oder Antriebe in wiederkehrenden Prozessen.
Wichtig ist außerdem eine Architektur, die zur Realität der Anlage passt. In verteilten Infrastrukturen oder bei Standorten mit schwankender Anbindung ist Edge-first oft die vernünftigere Wahl als ein Cloud-only-Ansatz. Die Daten laufen lokal zusammen, Entscheidungen werden vor Ort vorbereitet und nur relevante Ereignisse gehen in die zentrale Plattform.
Ich würde außerdem vier messbare Kennzahlen von Anfang an festlegen: MTBF, also die mittlere Zeit zwischen zwei Ausfällen; MTTR, also die mittlere Reparaturzeit; die Quote falscher Alarme; und die Zahl vermiedener ungeplanter Stillstände. Ohne diese Zahlen bleibt der Nutzen subjektiv. Mit ihnen lässt sich nach wenigen Monaten sehr klar sehen, ob das Projekt trägt oder nur Daten sammelt.
Für die Umsetzung halte ich offene Schnittstellen für wichtiger als ein möglichst großes Dashboard. OPC UA, MQTT und saubere Rollenmodelle helfen mehr als ein hübsches Frontend, wenn später mehrere Lieferanten, Maschinenklassen oder Standorte dazukommen. Genau hier entscheidet sich oft, ob ein System langfristig tragfähig bleibt oder nach dem Pilotprojekt stecken bleibt.
Was von einem guten Pilotprojekt am Ende bleiben sollte
Ein gutes Pilotprojekt liefert am Ende nicht nur ein paar schöne Grafiken, sondern eine belastbare Betriebslogik. Ich erwarte dann, dass klar ist, welches Asset überwacht wird, welche Signale wirklich tragen, wie ein Alarm ausgelöst wird und wer darauf reagiert. Wenn diese Kette funktioniert, ist der schwierigste Teil schon geschafft.
- Ein klar abgegrenzter Anwendungsfall mit einem realen Fehlerbild
- Ein sauberer Datenpfad vom Sensor bis zum Wartungsauftrag
- Ein definierter Schwellenwert oder ein Modell mit nachvollziehbarer Güte
- Ein Verantwortlicher für Sensorpflege, Modellpflege und Alarmreaktion
- Eine einfache Entscheidung, ob das System skaliert, angepasst oder beendet wird
Wenn ein Pilot diese Punkte nicht erfüllt, ist er meist nur ein Monitoring-Projekt mit anderem Namen. Wenn er sie erfüllt, wird aus IoT-gestützter Wartung ein echter Hebel für Verfügbarkeit, Planbarkeit und eine deutlich ruhigere Instandhaltung.