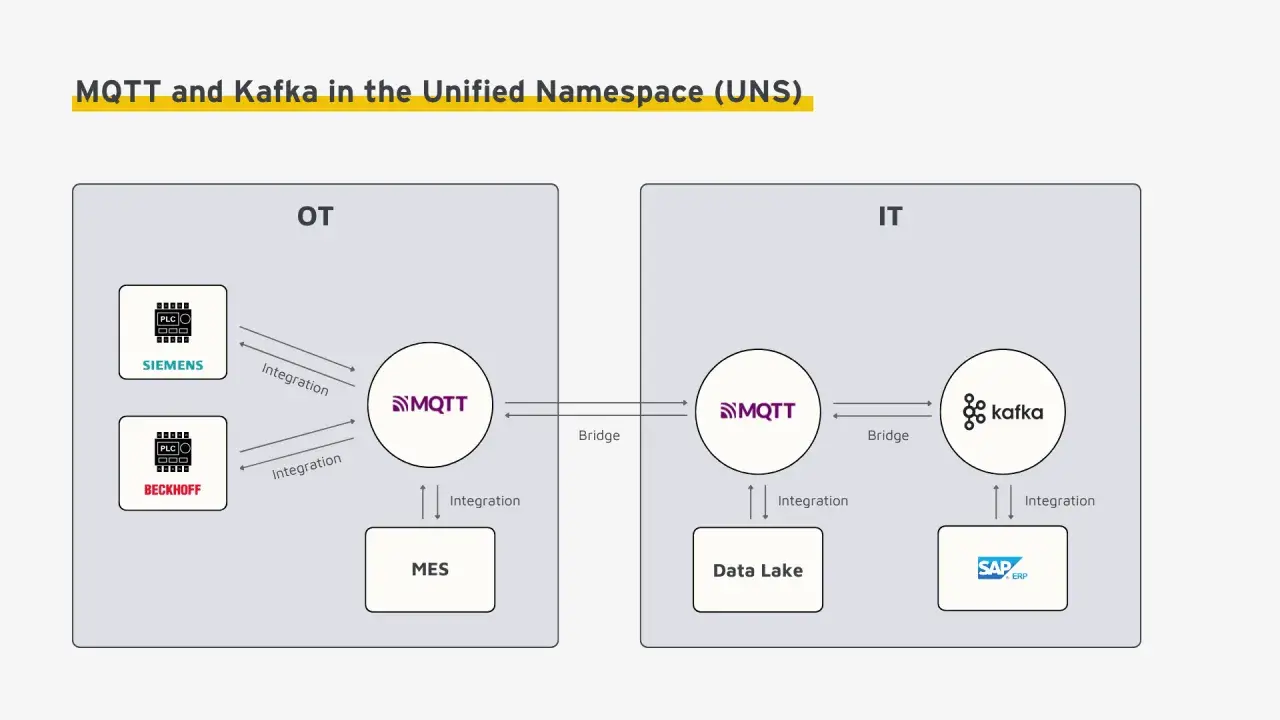
Bei IoT-Systemen entscheidet nicht der einzelne Broker über den Erfolg, sondern die Trennlinie zwischen Feldgeräten, Gateways und Datenplattform. MQTT hält die Kommunikation mit Sensoren, Zählern und Steuerungen schlank, während Kafka Ereignisse dauerhaft aufnimmt, verteilt und für mehrere Auswertungen verfügbar macht. Genau deshalb lohnt sich der Blick auf beide Technologien zusammen: nicht als Konkurrenz um den gleichen Job, sondern als saubere Aufteilung der Aufgaben.
Die sauberste Aufteilung liegt zwischen Feldkommunikation und Datenrückgrat
- MQTT ist für Geräte, Gateways und schwächere Verbindungen gebaut, Kafka für langlebige Streams und mehrere Konsumenten.
- Ein MQTT-Topic ist vor allem Routing, ein Kafka-Topic ein partitionierter Ereignisstrom mit Aufbewahrung.
- In vielen IoT-Architekturen gehört MQTT an den Rand und Kafka ins Zentrum.
- Die Übergabestelle ist meist ein Gateway oder ein Connector, nicht das Endgerät selbst.
- QoS, Retention, Partitionierung und Schema-Versionen müssen gemeinsam geplant werden.
Worin sich Kafka und MQTT grundlegend unterscheiden
Der wichtige Punkt ist nicht nur die Technik, sondern das Datenmodell. MQTT ist ein leichtgewichtiges Publish/Subscribe-Protokoll für Geräte mit knappen Ressourcen; Kafka ist ein verteiltes Event-Streaming-System für dauerhafte Streams, Parallelität und Wiederholung. Der gleiche Begriff „Topic“ täuscht ein bisschen: Bei MQTT ist es vor allem ein Routing- und Filterkonzept, bei Kafka ein partitionierter, geordneter Datenstrom mit Aufbewahrung.
| Kriterium | MQTT | Kafka | Was das in der Praxis bedeutet |
|---|---|---|---|
| Ziel | Kommunikation mit Geräten und Gateways | Dauerhaftes Ereignisrückgrat für viele Systeme | MQTT gehört näher ans Feld, Kafka näher an Analyse und Integration. |
| Ressourcenbedarf | Sehr leichtgewichtig | Cluster-basiert und schwerer | MQTT passt besser zu kleinen Geräten und instabilen Links. |
| Zustellung | QoS 0, 1 oder 2, dazu Retain-Funktionen | Partitionierte Streams, Replikation und Consumer Groups | MQTT optimiert Zustellung, Kafka Wiederholung und Skalierung. |
| Aufbewahrung | Letzter Zustand pro Topic ist wichtig | Retention nach Zeit oder Größe, standardmäßig oft 7 Tage bei Delete-Policy | Kafka ist für Historie und Replay gebaut, nicht nur für den letzten Wert. |
| Skalierung | Broker und Verbindungen | Partitionen, Replikate und parallele Konsumenten | Wenn mehrere Systeme dieselben Daten brauchen, spielt Kafka seinen Vorteil aus. |
| Typische Rolle | Telemetrie, Kommandos, Statusmeldungen | Streaming, Monitoring, Data Lake, Event-Driven Architecture | Das ist die Trennung, die in IoT-Projekten am saubersten funktioniert. |
Ich merke mir es so: MQTT spricht mit dem Gerät, Kafka spricht mit dem Rest der Organisation. MQTT liefert schlanke Zustellung und kann mit QoS 0/1/2 arbeiten, Kafka liefert Partitionen, Replikation und Replay. Wer beide mit derselben Erwartung an Latenz oder Persistenz bewertet, plant am Ziel vorbei. Genau an dieser Stelle wird die Frage spannend, wann beide Ebenen zusammenarbeiten sollten.
Wann sich beide zusammen wirklich lohnen
Ich setze die Kombination vor allem dort ein, wo Geräte nur sporadisch online sind, die Zentrale aber viele Konsumenten hat: Monitoring, Alarmierung, Reporting, Data Lake, Wartungsplanung. In Telekommunikations- oder Infrastrukturumgebungen sind das oft Außenstationen, Feldsensoren, Energiezähler oder Geräte an Standorten mit schwankender Anbindung.
- Ja, wenn Telemetrie an einem Ort erzeugt, aber in mehreren Teams verarbeitet wird.
- Ja, wenn Daten später erneut ausgewertet oder mit anderen Streams korreliert werden müssen.
- Ja, wenn Befehle zurück an Geräte gehen, die Analyse aber zentral bleiben soll.
- Ja, wenn Edge und Cloud getrennt betrieben werden und ein Puffer gebraucht wird.
- Nein, oft nicht wenn ein kleines System nur Live-Kommunikation ohne historische Auswertung braucht.
Für kleine Installationen mit wenigen Geräten ist ein reiner MQTT-Ansatz oft völlig ausreichend. Kafka bringt dort schnell mehr Betriebsaufwand als Nutzen. Die Kombination lohnt sich erst dann wirklich, wenn aus einer einfachen Gerätekette ein belastbarer Datenfluss für mehrere Anwendungen werden muss. Sobald die Kombination sinnvoll ist, muss die Übergabe zwischen den Welten sauber definiert werden.
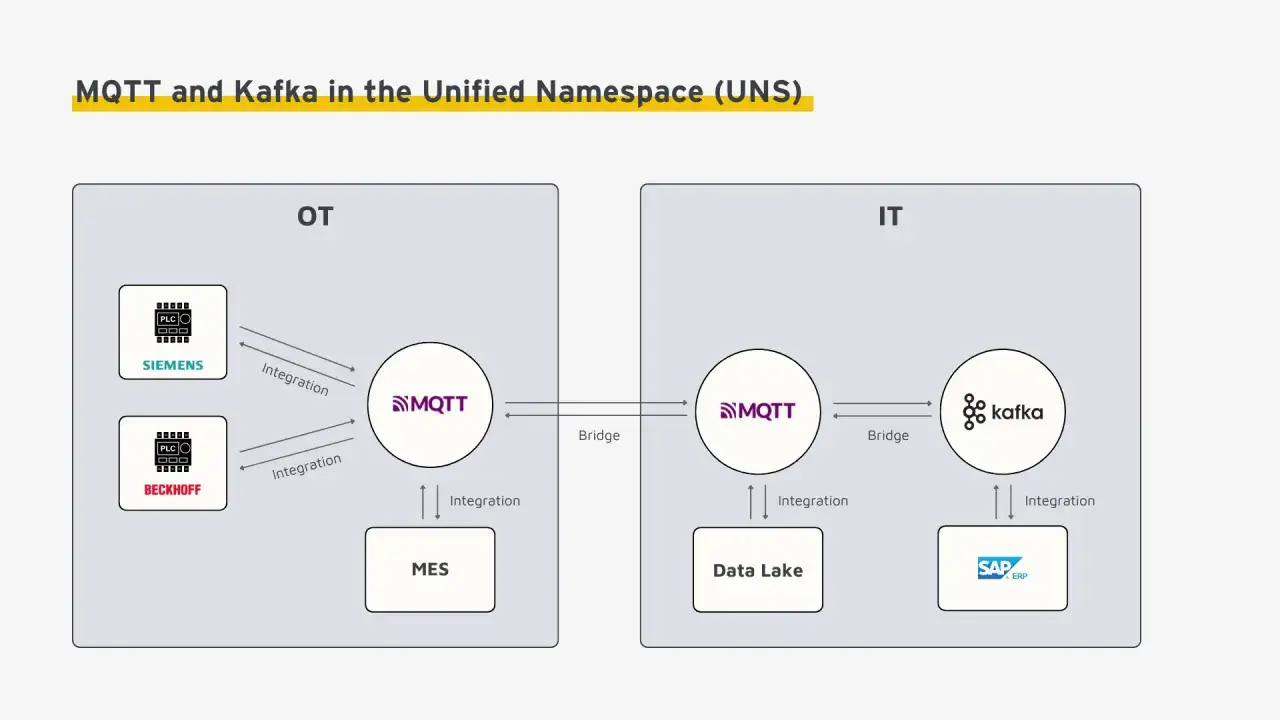
Drei Integrationsmuster, die ich in der Praxis bevorzuge
Vom MQTT-Broker ins Kafka-Backbone
Das ist das häufigste Muster. Ein Source-Connector oder ein kleiner Bridge-Service liest Topics vom MQTT-Broker und schreibt die Ereignisse in Kafka. So bleiben Geräte und Gateways leichtgewichtig, während die Plattform Historie, Parallelität und Wiederverarbeitung bekommt. Für Telemetrie ist das meistens die sauberste Linie.
Vom Kafka-Stream zurück ins Feld
Für Setpoints, Wartungsbefehle oder Firmware-Trigger drehe ich den Weg um. Kafka speichert den Befehl, ein Sink-Connector oder Gateway publiziert ihn in MQTT, und das Gerät bekommt ihn mit der für sein Profil passenden Zustellung. Das ist besonders nützlich, wenn Befehle nachvollziehbar bleiben sollen, aber am Ende trotzdem auf einem schlanken Protokoll ankommen müssen.
Lesen Sie auch: Industrielles IoT - So schaffen Sie echten Mehrwert & Sicherheit
Gateway mit Puffer und Übersetzung
Wenn Verbindungen instabil sind, setze ich zuerst auf einen Edge-Gateway-Ansatz. Das Gateway sammelt lokal, puffert bei Ausfällen und übersetzt erst danach in Kafka. Diese Variante ist operativ aufwendiger, verhindert aber Datenverlust bei kurzen oder längeren Netzunterbrechungen. Gerade in verteilten Infrastrukturen ist das oft der Unterschied zwischen „läuft“ und „läuft auch noch nach einem Ausfall“.
Kafka Connect ist für solche Brücken ein guter Standard, weil es genau für den Datentransfer zwischen Kafka und anderen Systemen gebaut ist. Der Vorteil ist nicht nur Konnektivität, sondern auch die klare Trennung von Quelle, Ziel, Tasks und Verarbeitung. Bevor so eine Brücke produktiv geht, müssen Datenmodell und Zustellsemantik zusammenpassen.
So plane ich Datenmodell, Reihenfolge und Zustellsemantik
Hier gehen viele Projekte leise schief, weil sie nur an Protokolle denken. Ich plane zuerst die Bedeutung der Nachricht: Messwert, Zustand, Alarm, Befehl oder Diagnose. Erst danach definiere ich Topic-Struktur, Partition-Schlüssel und Aufbewahrung.
| Thema | Empfehlung | Warum das hilft |
|---|---|---|
| Partition-Schlüssel | Geräte-ID oder Standort-ID verwenden | So bleibt die Reihenfolge pro Gerät oder Standort nachvollziehbar. |
| MQTT QoS | QoS 0 für unkritische Telemetrie, QoS 1 für wichtige Werte | QoS 1 reduziert Verluste, erzeugt aber Duplikate, die Downstream verarbeitet werden müssen. |
| Kafka-Retention | Historie bewusst festlegen, nicht dem Standard überlassen | Kafka hält Daten nicht „für immer“; die Aufbewahrung ist ein Architekturparameter. |
| Zustand | Retained Messages nur für den letzten bekannten Wert nutzen | MQTT-Retain ist ideal für aktuellen Status, nicht für Analysehistorie. |
| Fehlertoleranz | Bei kritischen Streams mit `acks=all` und ausreichender Replikation arbeiten | So sinkt das Risiko, dass bestätigte Nachrichten bei einem Ausfall verschwinden. |
| Schema | Versionierte JSON-, Avro- oder Protobuf-Modelle festlegen | Ohne Schema-Plan wird jedes Geräteupdate schnell zum Integrationsproblem. |
Ein praktischer Grenzfall ist der Unterschied zwischen retained message und Kafka-Retention. MQTT hält den letzten bekannten Zustand pro Topic, Kafka hält Ereignisse über einen Zeitraum oder bis zur Größenbegrenzung auf Partitionsebene; bei der Delete-Policy liegt die zeitbasierte Standardaufbewahrung oft bei 7 Tagen, wenn man sie nicht anpasst. Das ist keine Kleinigkeit, sondern entscheidet darüber, ob ein System nur den letzten Status kennt oder echte Historie besitzt. Wenn die Daten sauber modelliert sind, tauchen die typischen Fehler meist erst im Betrieb auf.
Typische Fehler, die ich in IoT-Projekten immer wieder sehe
- MQTT als Archiv behandeln. Das Protokoll ist gut für Zustellung und Zustandsnähe, nicht für Langzeitaufbewahrung.
- QoS 1 mit genau einmal verwechseln. Es ist mindestens einmal, also muss Downstream Duplikate vertragen oder entfernen.
- Topics 1:1 spiegeln, ohne Fachmodell. Dann landen Geräte-, Standort- und Alarmdaten chaotisch nebeneinander.
- Connector-Konfigurationen später hektisch ändern. Bei manchen Setups führen geänderte Task-Zahlen oder Topic-Zuordnungen zu Lücken oder Doppelungen.
- Rohbytes ohne Schema-Plan einführen. Wer die Struktur nicht versioniert, zahlt die Rechnung beim nächsten Geräte-Firmware-Update.
- Backhaul-Bandbreite zu spät mitdenken. Wer zu viel Rohdatenverkehr aus dem Feld zieht, macht aus der Datenplattform ein Netzwerkproblem.
Ich prüfe deshalb früh, welche Nachrichtentypen wirklich über Kafka laufen müssen und welche am Rand bleiben dürfen. Das spart Bandbreite, Betrieb und Fehlersuche. Am Ende geht es nicht um Technologie-Purismus, sondern um die robusteste Trennung der Aufgaben.
Welche Architektur sich 2026 in verteilten Netzen meist durchsetzt
Für 2026 ist meine Standardempfehlung klar: MQTT an den Geräten, Kafka im Zentrum. Das ist die stabilste Aufteilung, wenn Telemetrie aus vielen Außenstellen kommt, mehrere Teams darauf zugreifen und Daten später noch einmal analysiert oder mit anderen Quellen kombiniert werden sollen.
Nur MQTT reicht, wenn das System klein ist und vor allem Live-Kommunikation braucht. Nur Kafka reicht selten bis ans Feld, weil Endgeräte und schwache Links davon kaum profitieren. In den meisten Infrastruktur- und IoT-Setups gewinnt die Kombination aus leichtem Edge-Transport, lokalem Puffer und zentralem Event-Streaming.
Wenn ich zwischen beiden Welten entscheiden muss, frage ich zuerst nach drei Dingen: Muss das Gerät schlank bleiben, muss der Stream später replaybar sein und muss die Verbindung auch bei Unterbrechungen verzeihen können? Wenn zwei dieser drei Antworten „ja“ sind, plane ich die Brücke zwischen MQTT und Kafka von Anfang an mit ein.