
NETCONF und YANG gehören zu den Werkzeugen, die Netzbetrieb deutlich sauberer machen, wenn Konfigurationen nicht mehr per Hand auf dutzenden Geräten gepflegt werden sollen. NETCONF liefert den standardisierten Änderungsweg, YANG beschreibt die Datenstruktur dahinter; zusammen schaffen sie eine verlässliche Basis für automatisierte Netzverwaltung, Validierung und Rollback. Für Betreiber mit vielen Standorten, verteilten Teams oder sensibler Infrastruktur ist das kein Luxus, sondern ein Weg, Fehler und Betriebsaufwand spürbar zu senken.
Die Kombination aus Modell und Protokoll macht Netzbetrieb planbar
- NETCONF überträgt Konfigurationsänderungen als strukturierte RPCs, meist über SSH, alternativ auch über TLS.
- YANG beschreibt, welche Daten, Werte und Operationen auf einem Gerät überhaupt gültig sind.
- Mit NMDA, YANG Library und Call Home lässt sich der Betrieb stärker automatisieren und sicherer fernsteuern.
- Für komplexe Netze ist der größte Vorteil nicht Tempo, sondern Konsistenz, Validierung und kontrollierter Rollback.
- RESTCONF und CLI lösen ähnliche Aufgaben, sind aber für andere Betriebsmodelle besser geeignet.
Die Kernidee hinter NETCONF und YANG
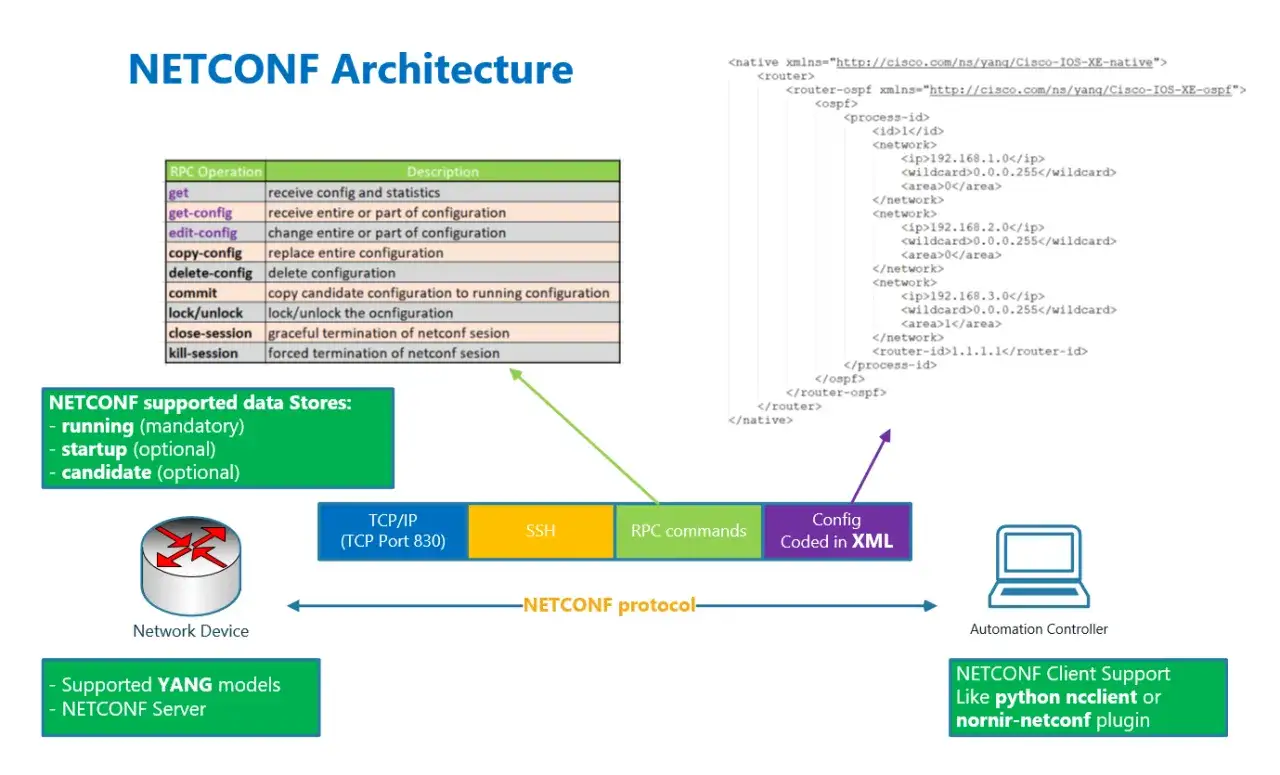
Ich trenne in Projekten immer zuerst zwischen Protokoll und Modell. NETCONF überträgt die Änderung, meist über SSH, alternativ über TLS, während YANG festlegt, wie Konfigurationsdaten, Zustände und Operationen strukturiert sind. Genau deshalb ist die Kombination so nützlich: Der Controller spricht nicht mit einem frei formulierten Befehlsstrom, sondern mit einem Schema, das der Server versteht und validieren kann.
Die IETF beschreibt NETCONF in RFC 6241 und YANG 1.1 in RFC 7950. Dazu kommt heute die NMDA-Sicht, also eine Architektur, die Konfigurations- und Betriebsdaten klarer trennt. In der Praxis bedeutet das: weniger Interpretationsspielraum, weniger Überraschungen beim Rollout und deutlich mehr Transparenz, wenn ein Gerät etwas akzeptiert oder ablehnt.
- NETCONF ist das Transport- und Änderungsprotokoll.
- YANG ist die Modellbeschreibung der Datenstruktur.
- NMDA trennt Konfigurations- und Betriebszustand sauberer voneinander.
Genau an dieser Trennung zeigt sich, warum die einzelnen YANG-Bausteine so wichtig sind.
Welche Bausteine YANG wirklich beschreibt
YANG ist mehr als ein Schema. Das Modell beschreibt, welche Knoten, Werte und Operationen existieren, wie sie zusammenhängen und welche Regeln gelten. Wer nur an Felder denkt, übersieht die eigentlich wichtigen Teile: Erweiterbarkeit, Wiederverwendung und die Möglichkeit, auch Aktionen und Ereignisse mitzubeschreiben.
- leaf ist ein einzelner Wert, etwa eine IP-Adresse oder ein Verwaltungsstatus.
- container fasst logisch zusammengehörige Daten.
- list steht für wiederholbare Einträge, zum Beispiel Interfaces oder Nachbargeräte.
- augment erweitert ein bestehendes Modell, ohne es komplett neu zu schreiben.
- rpc beschreibt eine auslösbare Operation, etwa einen Testlauf oder einen Reset.
- notification liefert Ereignisse an abonnierende Systeme, also zum Beispiel Link-Down oder Konfigurationsänderungen.
Über die YANG Library kann ein Gerät zusätzlich anzeigen, welche Module, Revisionen und Datastores es wirklich unterstützt. Ich halte diesen Abgleich für Pflicht, weil Automatisierung ohne Modul- und Versionsprüfung schnell auf Annahmen aufbaut, die nur auf dem Laborsystem stimmen.
Genau an diesem Punkt zeigt sich, warum das im Netzbetrieb wirtschaftlich relevant ist.
Warum das für den Betrieb realer Netze zählt
Für Betreiber zählt am Ende nicht die Eleganz des Standards, sondern der Effekt im Tagesgeschäft. In Netzen mit vielen Außenstandorten, begrenzten Vor-Ort-Einsätzen und wechselnden Teams reduziert schema-gestützte Fernverwaltung vor allem drei Dinge: Tippfehler, inkonsistente Konfigurationen und langes Troubleshooting nach einem manuellen Eingriff.
Ein typischer Vorteil ist die Template-Logik: Ein neuer Standort bekommt nicht 20 freihändig eingegebene CLI-Kommandos, sondern ein geprüftes Datenmodell für VLANs, Adressen, QoS-Regeln und Zugriffslisten. Wenn ein Wert nicht passt, lehnt der Server ihn ab, bevor er produktiv Schaden anrichtet. Genau das ist in Telekommunikations- und Infrastrukturumgebungen wertvoll, etwa bei Router-Farmen, Aggregationsknoten, OLTs oder Richtfunkstrecken.
Ich sehe diesen Ansatz besonders dann als stark, wenn ein zentrales NOC viele Geräte verwaltet, der Weg zum Standort lang ist oder ein Rollback im Fehlerfall teuer wäre. Dann spart nicht nur die Automatisierung Zeit, sondern auch die saubere Validierung vor dem Commit. Der praktische Ablauf dahinter ist nüchtern, aber genau darin liegt seine Stärke.
So läuft eine Änderung in der Praxis ab
In einem sauberen Setup läuft eine Änderung nicht als blindes Überschreiben, sondern als kontrollierte Folge von Schritten. Ich plane sie typischerweise so:
- Der Controller liest die unterstützten Module, Revisionen und Datastores des Geräts aus.
- Er baut daraus eine gültige Datenstruktur nach dem YANG-Modell.
- Vor dem Schreiben prüft er Pflichtfelder, Datentypen, Referenzen und Wertebereiche.
- Die Änderung wird in den vorgesehenen Datastore geschrieben und nach Möglichkeit gesperrt, damit nicht zwei Systeme gleichzeitig daran arbeiten.
- Mit einem confirmed commit kann der Rollout abgesichert werden: Wird er nicht rechtzeitig bestätigt, fällt das Gerät auf den vorherigen Stand zurück.
- Notifications oder Telemetrie zeigen danach, ob der Link, das Interface oder die Sitzung stabil bleibt.
Für abgelegene oder schwer erreichbare Standorte ist zusätzlich Call Home interessant. Dabei initiiert das Gerät die sichere Verbindung selbst, was besonders hilft, wenn eingehende Managementzugänge hinter NAT, Firewalls oder unzuverlässigen Zugängen liegen. Das ist kein Muss, aber in vielen realen Netzen der Unterschied zwischen theoretisch sauber und praktisch gut wartbar.
Als Nächstes lohnt sich der Blick auf die Frage, wo NETCONF in der Tool-Landschaft wirklich besser passt als die Alternativen.
NETCONF, RESTCONF und die klassische CLI im Vergleich
In der Praxis wird NETCONF oft gegen RESTCONF oder die klassische CLI gestellt. Das ist sinnvoll, solange man ehrlich über den Einsatzzweck bleibt: Nicht jedes Werkzeug muss alles können.
| Kriterium | NETCONF | RESTCONF | CLI |
|---|---|---|---|
| Grundlage | RPC-basiertes Protokoll über SSH oder TLS | HTTP-basiertes API auf YANG-Daten | Interaktive Befehlszeile des Herstellers |
| Datenmodell | Strikt schema- und datastore-orientiert | Ebenso YANG-basiert | Oft proprietär und befehlsorientiert |
| Stärken | Saubere Transaktionen, Validierung, Rollback | Leicht in Web- und API-Stacks integrierbar | Schnell für Diagnose und manuelle Eingriffe |
| Schwächen | Einarbeitung und XML-basierte RPC-Struktur sind höher | Für komplexe, mehrstufige Änderungen weniger komfortabel | Fehleranfällig bei Wiederholung und Skalierung |
| Typischer Einsatz | Provisionierung, Massenänderungen, kontrollierte Rollouts | Northbound-Integrationen und einfache Automatisierung | Troubleshooting und Notfallbetrieb |
Mein pragmatisches Urteil: Wenn du viele Geräte konsistent verwalten willst, ist NETCONF meist die robustere Basis. Wenn du ein API-freundliches Frontend brauchst, ist RESTCONF oft der bequemere Zugang. Die CLI bleibt nützlich, aber sie ist kein guter Primärweg für reproduzierbare Netzautomatisierung. Genau deshalb stolpern Projekte oft nicht am Standard selbst, sondern an den Details der Umsetzung.
Typische Fehler, die Projekte unnötig teuer machen
Die meisten Probleme entstehen nicht am Protokoll selbst, sondern an Annahmen rundherum. Ich sehe immer wieder dieselben Fallen:
- Module und Revisionen nicht prüfen: Ein Gerät kann NETCONF unterstützen, aber nicht das erwartete YANG-Modul oder nur eine andere Revision davon.
- Konfiguration und Zustand vermischen: Betriebsdaten sind nicht automatisch Konfigurationsdaten. Wer beides durcheinanderbringt, jagt falschen Alarmen hinterher.
- Vendor-Modelle als portabel behandeln: YANG standardisiert viel, aber nicht alles. Erweiterungen einzelner Hersteller müssen bewusst eingeplant werden.
- Zugriffsrechte zu grob setzen: Ohne sauberes NACM, also das Access-Control-Modell für NETCONF, sind Schreibrechte schnell zu weit geöffnet.
- Rollback nie testen: Ein Commit, der sich im Labor gut anfühlt, ist wertlos, wenn der Rückweg im Fehlerfall nicht sauber funktioniert.
- Transport und Erreichbarkeit unterschätzen: Wenn das Gerät nicht zuverlässig erreichbar ist, braucht man rechtzeitig Call Home, passende Firewalls und saubere Zertifikate.
Diese Punkte wirken banal, entscheiden aber oft darüber, ob ein Projekt als Automatisierungsplattform wächst oder als weiteres Skriptmuseum endet. Genau deshalb prüfe ich im letzten Schritt immer die Betriebsbedingungen, nicht nur das Datenmodell.
Worauf ich bei einem Netzprojekt zuerst achte
Bevor ich NETCONF/YANG als Standardpfad empfehle, kläre ich sechs Dinge: Welche Geräte und Module sind wirklich vorhanden, welche Revisionen sind freigegeben, wie werden Änderungen validiert, wer darf schreiben, wie läuft der Rollback und über welchen Transport kommt die Verbindung zustande. Erst wenn diese Antworten sauber sind, lohnt sich die Skalierung auf mehrere Standorte oder auf einen zentralen Orchestrator.
- Ein verlässlicher Modul- und Versionskatalog verhindert spätere Überraschungen.
- Ein klarer Freigabeprozess für Changes hält Automatisierung und Betrieb zusammen.
- Schema-Validierung vor dem Commit spart Ausfälle, die man später teuer zurückrollen müsste.
- Schreibrechte, Protokollierung und Alarmierung gehören von Anfang an in die Architektur.
Gerade in Telekommunikations- und Infrastrukturnetzen mit weit verteilten Punkten, begrenzten Vor-Ort-Fenstern und hohem Verfügbarkeitsdruck zahlt sich diese Disziplin schnell aus: Nicht der Standard allein macht ein Netz besser, sondern die saubere Kombination aus Modell, Transport, Freigabe und Rückfallstrategie.