Segment Routing verschiebt einen Teil der Pfadlogik direkt in das Paket und macht Verkehrssteuerung dadurch planbarer und oft einfacher zu betreiben. In diesem Artikel zeige ich, wie das Prinzip funktioniert, worin der Unterschied zwischen SR-MPLS und SRv6 liegt und welche Kompromisse man im Alltag realistisch einplanen muss. Gerade für Transport- und Backbone-Netze ist das relevant, wenn Pfade gezielt geführt, Lasten besser verteilt und Betriebsaufwand reduziert werden sollen.
Die wichtigsten Punkte auf einen Blick
- Segment Routing ist ein Source-Routing-Ansatz: Das Paket trägt eine geordnete Liste von Anweisungen, die den Weg bestimmen.
- Die Steuerung sitzt vor allem am Headend, also am Eintrittspunkt des Verkehrs, nicht in jedem Zwischenknoten.
- Im Kern gibt es zwei etablierte Datenebenen: SR-MPLS und SRv6.
- Besonders stark ist die Technik bei Traffic Engineering, definierten Ausweichpfaden und servicebezogener Verkehrslenkung.
- Typische Stolpersteine sind Header-Overhead, SID-Planung, MTU-Fragen und eine zu schnelle Migration.
Was das Verfahren im Kern macht
Ich fasse es bewusst schlicht: Ein Paket bekommt am Rand des Netzes eine Route oder eine Befehlsfolge mit auf den Weg. Zwischengeräte müssen dann nicht mehr für jeden einzelnen Flow eigene Zustände halten, sondern folgen den Anweisungen, die bereits im Paket stecken. Genau das ist der eigentliche Reiz dieser Architektur, weil sie Steuerung und Weiterleitung sauberer trennt als viele klassische Ansätze.
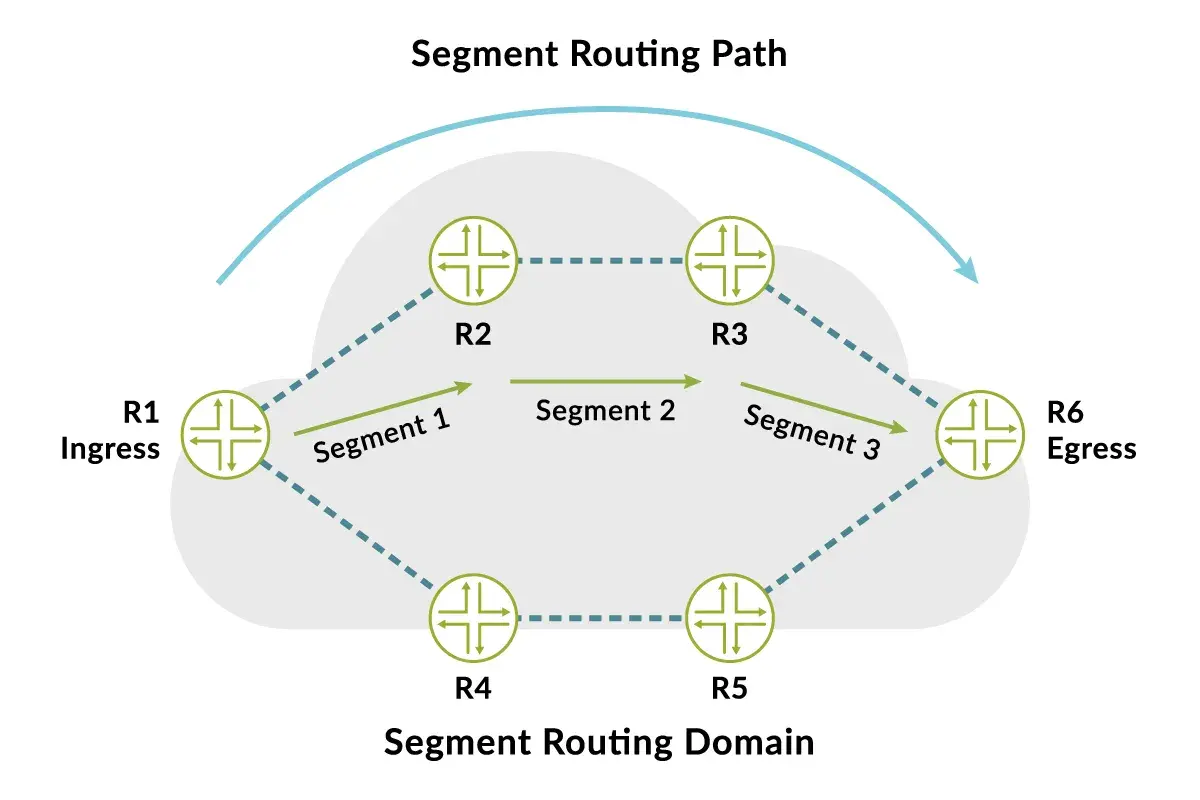
In der Praxis tauchen dabei drei Begriffe immer wieder auf. Ein SID ist ein Segment Identifier, also die codierte Anweisung. Der Headend ist der Knoten, der diese Anweisungen ins Paket schreibt. Und eine SR Policy ist die geordnete Liste von Segmenten, die für ein bestimmtes Ziel oder einen bestimmten Zweck gelten soll.
- Topologische Segmente führen über einen bestimmten Pfad im Netz, etwa über einen gewünschten Transitknoten.
- Service-basierte Segmente lenken den Verkehr zu einer Funktion, zum Beispiel zu einem Sicherheits- oder Analysepunkt.
- Per-flow state bleibt am Eintrittspunkt konzentriert und verteilt sich nicht unnötig über den gesamten Kern.
Praktisch bedeutet das: Ich kann Verkehr gezielter lenken, ohne das gesamte Routingmodell auf den Kopf zu stellen. Das wird besonders interessant, sobald man nicht nur „den kürzesten Weg“, sondern einen bewusst gewählten Weg braucht. Genau dort setzt der nächste Schritt an, nämlich die Frage, wie diese Anweisungen tatsächlich im Paket landen.
Wie der Pfad im Paket landet
Technisch gibt es zwei verbreitete Arten, diese Befehlsfolge zu codieren. Bei SR-MPLS wird ein Segment als MPLS-Label dargestellt. Bei SRv6 wird ein Segment als IPv6-Adresse beziehungsweise als Eintrag im Segment Routing Header transportiert. Die Grundidee ist aber identisch: Das Paket trägt eine Liste von Stationen oder Aufgaben mit sich.
- Der erste Knoten im Pfad, also das Headend, wählt die passende Policy aus.
- Er schreibt die Segmentliste in den Paketkopf.
- Jeder Transitknoten verarbeitet das aktive Segment und rückt dann zum nächsten weiter.
- Am Ende wird das Paket an das eigentliche Ziel oder an eine definierte Netzwerkfunktion übergeben.
Entscheidend ist dabei, dass die Reihenfolge nicht zufällig ist. Ein Segment kann den Verkehr zum nächsten Knoten führen, das nächste kann einen bestimmten Service auslösen, und ein weiteres kann die letzte Zustellung präzisieren. Ich halte das für einen der Gründe, warum SR mehr ist als nur ein moderneres Routing-Label: Es lässt sich als kleines, aber sehr gezieltes Steuerungsprogramm im Paket lesen.
In betrieblichen Designs wird eine Policy oft über Headend, Color und Endpoint beschrieben. Der Headend-Knoten setzt den Pfad um, der Endpoint markiert das Ziel, und der Color-Wert steht sinngemäß für den beabsichtigten Zweck, etwa niedrige Latenz, bestimmte Serviceklasse oder einen alternativen Transportpfad. Diese Trennung wirkt zunächst technisch, spart aber im Betrieb viel Diskussion, weil Intent und Ziel eindeutiger werden.
Damit ist die Architektur klarer. Die nächste Frage ist deshalb naheliegend: Welche Datenebene ist für welches Netz die bessere Wahl?
SR-MPLS und SRv6 im Vergleich
Beide Varianten verfolgen dieselbe Logik, aber sie passen nicht in jede Umgebung gleich gut. SR-MPLS ist oft die naheliegende Wahl, wenn bereits ein MPLS-Backbone existiert und man die Forwarding-Ebene möglichst wenig anfassen will. SRv6 ist stärker, wenn IPv6 ohnehin eine zentrale Rolle spielt oder wenn man Netzwerkfunktionen und Pfadsteuerung enger zusammenbringen möchte.
| Aspekt | SR-MPLS | SRv6 |
|---|---|---|
| Datenebene | MPLS-Label-Stack | IPv6 plus Segment Routing Header |
| Stärke | Reifer Pfad für bestehende Provider-Backbones | Sehr flexible Netzwerkprogrammierung und stärkere IPv6-Nähe |
| Betriebsaufwand | Oft einfacher in MPLS-dominierten Netzen | Erfordert disziplinierte Locator- und SID-Planung |
| Overhead | Meist kompakter | Kann bei langen SID-Stacks deutlich wachsen |
| Typische Nutzung | Backbone, Transportnetz, Migration aus klassischem MPLS | Neue IPv6-zentrierte Netze, flexible Service-Steuerung, programmierbare Overlays |
Ich würde die Entscheidung nicht als ideologisch sehen. Wenn ein Netz heute stabil auf MPLS läuft, spricht viel für einen schrittweisen Ansatz mit SR-MPLS. Wenn dagegen IPv6 im Transport- und Service-Design bereits dominiert, kann SRv6 mehr langfristige Flexibilität liefern. Die bessere Wahl ist also weniger eine Glaubensfrage als eine Frage von Bestand, Teamgröße und Migrationszielen.
Für Betreiber ist diese Unterscheidung wichtig, weil sie direkt beeinflusst, wie schnell sich das Netz umbauen lässt. Genau dort zeigt sich auch, warum die Technik in Transportnetzen und regional verteilten Infrastrukturen so viel Aufmerksamkeit bekommt.
Wo die Technik im Backbone wirklich hilft
Der größte Nutzen entsteht nicht im Lehrbuch, sondern dort, wo man Verkehr bewusst unterscheiden muss. In Netzen mit mehreren Übergabepunkten, langen Verbindungen oder knappen Betriebsressourcen hilft ein klar steuerbarer Pfad oft mehr als noch ein zusätzliches Einzelprodukt. Besonders relevant wird das, wenn kritische Dienste nicht denselben Weg wie Massenverkehr nehmen sollen.
Verkehr gezielt lenken
Mit SR lässt sich Traffic Engineering sauberer abbilden. Ich kann beispielsweise einen Pfad mit niedrigerer Latenz für Echtzeitdienste wählen, einen anderen für Massenverkehr und einen dritten als Reserveweg. Das ist kein Luxus, sondern oft die einzige vernünftige Antwort, wenn das Netz unterschiedliche Dienstklassen zuverlässig bedienen soll.
Schnelle Ausweichpfade bei Störungen
Eine der praktischen Stärken ist die Kombination mit Schutzmechanismen wie TI-LFA, also Topology Independent Loop-Free Alternate. Vereinfacht gesagt wird ein Ersatzpfad so vorbereitet, dass er nach einem Ausfall schnell übernehmen kann, ohne auf die vollständige Konvergenz des gesamten Netzes zu warten. Das reduziert Paketverlust und macht den Betrieb spürbar robuster.
Lesen Sie auch: QUIC-Test - So prüfen Sie HTTP/3-Verbindungen richtig
Dienste sauber voneinander trennen
SRv6 geht hier noch einen Schritt weiter, weil nicht nur Wege, sondern auch Netzwerkfunktionen in der Segmentkette abgebildet werden können. Das ist nützlich, wenn Verkehr zum Beispiel erst durch eine Inspektionsfunktion, dann durch eine Servicekette und erst danach ins Zielnetz soll. Für mich ist genau das der Punkt, an dem aus einem Routing-Mechanismus eine echte Programmierlogik wird.
Besonders interessant ist das in geografisch verteilten Netzen, in denen nicht jeder Standort gleich gut angebunden ist. Dort kann eine saubere Pfadvorgabe helfen, knappe Ressourcen besser zu nutzen, Überlasten gezielter zu vermeiden und sensible Dienste getrennt zu behandeln. Der Nutzen ist also nicht abstrakt, sondern sehr operativ.
Grenzen, Risiken und typische Planungsfehler
Ich würde Segment Routing nie als Wundermittel verkaufen. Die Architektur kann vieles vereinfachen, aber sie verlagert Komplexität teilweise in Planung, Policies und Plattformgrenzen. Wer das übersieht, gewinnt am Anfang vielleicht Eleganz, später aber unnötige Betriebskosten.
- Header-Overhead unterschätzen - Gerade bei SRv6 wächst der Paketkopf mit jeder zusätzlichen Anweisung. Das kostet Platz und kann die effektive Nutzlast verringern.
- MTU nicht mitdenken - Mehr Kopfzeilen bedeuten schneller, dass Frames die zulässige Größe sprengen. Das rächt sich oft erst im Betrieb.
- Hardware-Fähigkeiten ignorieren - Nicht jeder Router verarbeitet lange Segmentstapel gleich gut. Die Forwarding-Leistung kann je nach Plattform unterschiedlich reagieren.
- Zu viel auf einmal einführen - Wer SR, neue Policies, neue Dienste und neue Betriebsmodelle gleichzeitig ändert, macht Fehlersuche unnötig schwer.
- Locator und SID-Planung nachlässig behandeln - Besonders bei SRv6 braucht die Adress- und Segmentstruktur klare Regeln, sonst wird der Betrieb schnell unübersichtlich.
Ein weiterer Punkt, den ich in Projekten immer prüfe: Nicht jede Plattform und nicht jede IGP-Kombination ist für einen Mischbetrieb gleich bequem. In manchen Umgebungen ist der Übergang von SR-MPLS zu SRv6 möglich, aber nicht ohne saubere Designgrenzen und eine klare Migrationsreihenfolge. Wer das früh ignoriert, baut sich eine fragile Zwischenlösung.
Mein Rat ist deshalb nüchtern: Erst die Randbedingungen prüfen, dann den Mehrwert messen, erst danach breit ausrollen. So bleibt die Architektur ein Werkzeug und wird nicht zum Selbstzweck.
Worauf ich bei einem Rollout zuerst achten würde
Wenn ich heute ein Transport- oder Backbone-Projekt mit Segment Routing bewerte, gehe ich in einer klaren Reihenfolge vor. Nicht die Technologie selbst entscheidet, sondern die Frage, ob sie zu den Betriebszielen passt und ob die Plattformen sie zuverlässig tragen.
- Verkehrsziele festlegen - Welche Pfade sollen bevorzugt werden, und welche Dienste brauchen eigene Behandlung?
- Die passende Datenebene wählen - Besteht das Netz bereits aus MPLS, oder soll IPv6 die tragende Schicht sein?
- Hardware und MTU prüfen - Können alle relevanten Knoten den gewünschten Segmentumfang und die nötige Paketgröße verarbeiten?
- Policy- und SID-Modell definieren - Wer vergibt Segmente, welche Bedeutung haben Farben oder Klassen, und wie bleibt das später nachvollziehbar?
- Mit einem begrenzten Anwendungsfall starten - Ich würde zuerst einen klar messbaren Pfad oder eine Dienstklasse umsetzen, statt gleich das ganze Netz umzubauen.
Am Ende ist genau das der praktische Maßstab: Die Technik lohnt sich dort, wo Pfadkontrolle, Skalierung und Automatisierung zusammen einen echten Betriebsvorteil ergeben. Für Backbone-, Provider- und regional verteilte Netze ist das oft der Fall, aber nur dann, wenn Design und Realität sauber zusammenpassen.