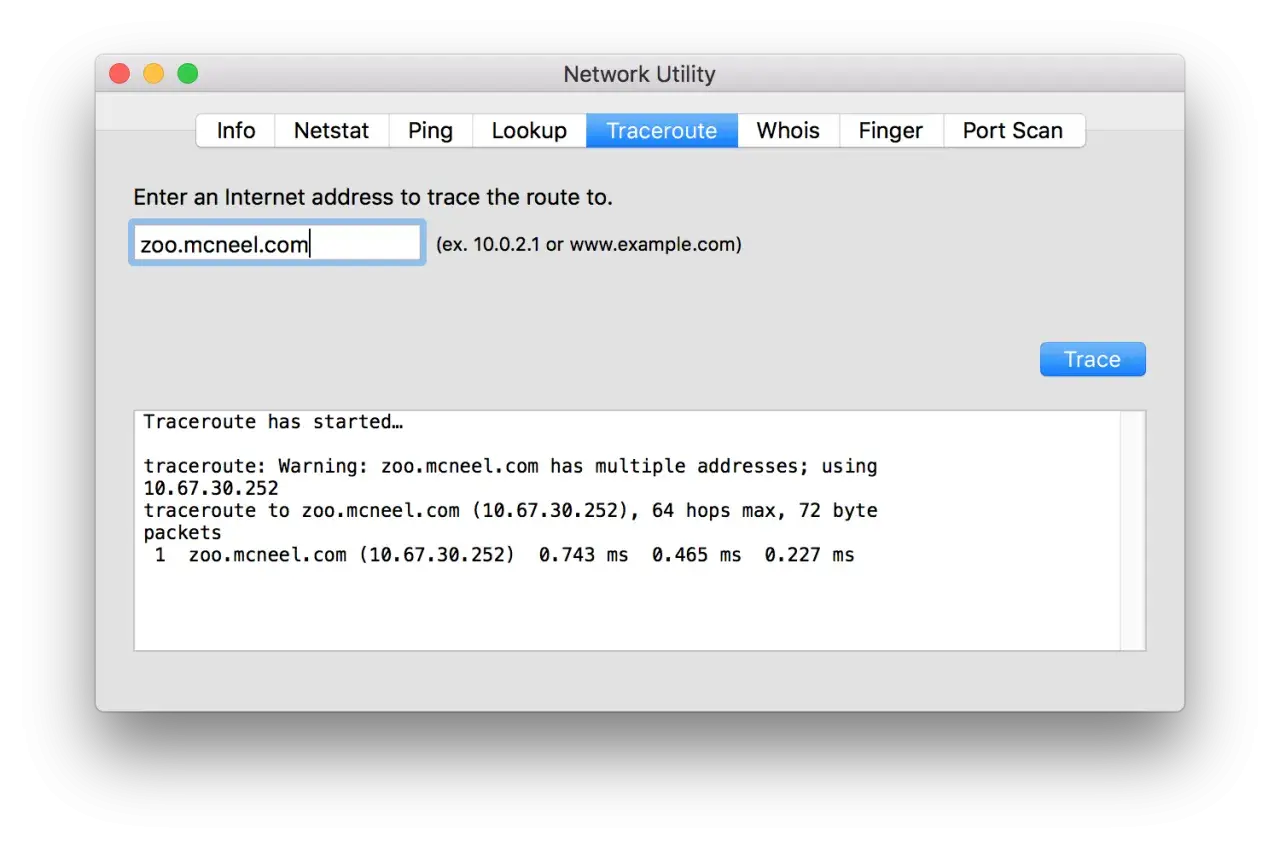
Auf dem Mac ist die sinnvolle Route eines Pakets oft schneller sichtbar, als viele denken. Hinter tracert mac steckt praktisch der Befehl traceroute: Er zeigt, über welche Zwischenstationen ein Paket läuft und an welcher Stelle Latenz, Verlust oder ein Filter ins Spiel kommen. Gerade bei WLAN-Problemen, VPN-Verbindungen oder internationalen Übergaben ist das oft der schnellste Weg zu einer belastbaren ersten Einschätzung.
Die wichtigsten Punkte in Kürze
- Auf macOS heißt das Werkzeug traceroute, nicht tracert.
- Der Befehl zeigt Hop für Hop, wo Pakete unterwegs sind und wo Verzögerungen entstehen.
- Standardmäßig sendet traceroute mehrere Probes pro Hop; das macht die Messung robuster.
- Mit -I wechselst du auf ICMP, wenn die normale UDP-Messung blockiert wird.
- -n, -q 1 und -w machen die Ausgabe schneller und oft lesbarer.
- Sterne, wechselnde Hops oder Timeouts bedeuten nicht automatisch einen kompletten Ausfall.
Was traceroute auf dem Mac eigentlich misst
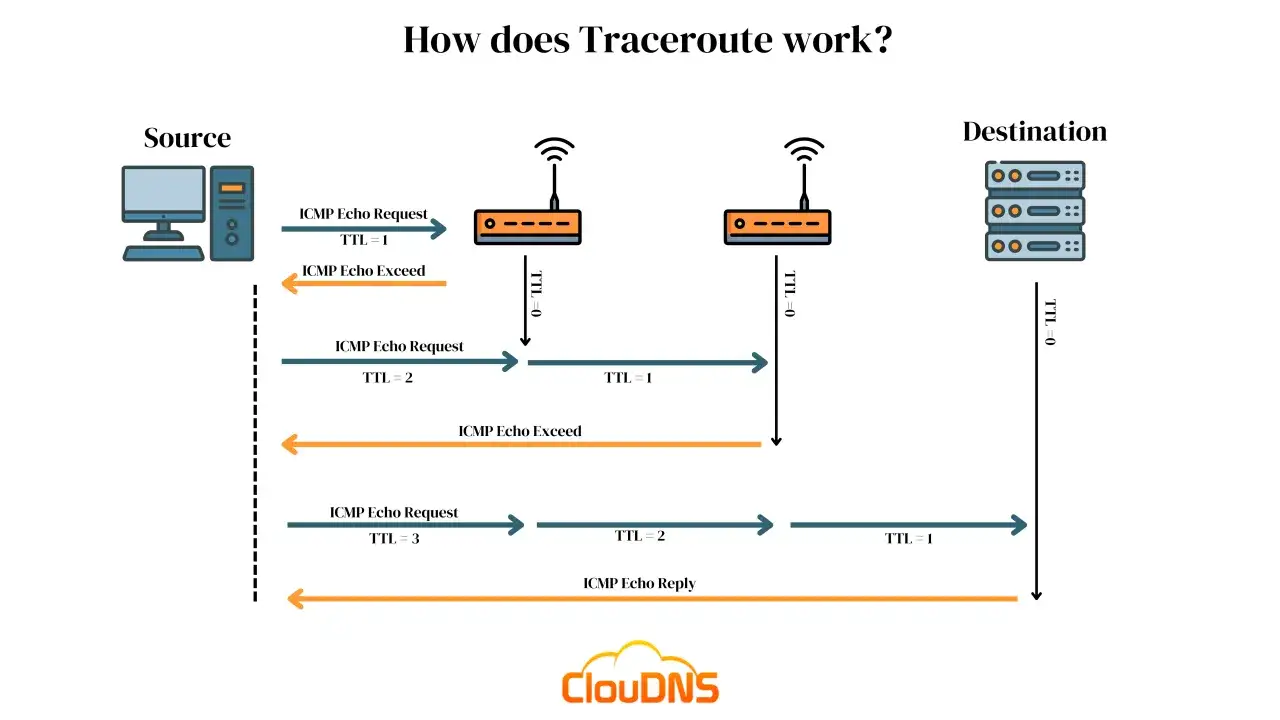
Ich denke bei traceroute immer zuerst an Pfadanalyse, nicht an einen bloßen Verbindungscheck. Das Kommando sendet Probes mit schrittweise steigender TTL, also einer Lebensdauer für IP-Pakete. Jeder Router auf dem Weg zieht einen Zähler ab, und wenn die TTL auf null fällt, meldet der Zwischenknoten typischerweise „Time Exceeded“. So lässt sich erkennen, über welche Hops die Pakete laufen und wo sie hängen bleiben oder auffällig langsam werden.
Wichtig ist dabei die Grenze der Methode: traceroute zeigt den Weg der Messpakete, nicht zwingend exakt den Weg aller Datenströme. Lastverteilung, asymmetrische Routen oder Sicherheitsfilter können das Bild verändern. Für Netze mit mehreren Übergaben, etwa zwischen lokalem Zugang, Provider und weiterem Transit, ist das trotzdem extrem nützlich, weil du die Störung grob lokalisieren kannst. Genau deshalb lohnt sich als Nächstes der praktische Start im Terminal.
So startest du die Analyse im Terminal
Auf aktuellen macOS-Versionen brauche ich dafür keine separate Netzwerk-App. Ich öffne einfach Terminal über Spotlight oder über die Dienstprogramme und setze den Test direkt dort an. Wenn du eine Zieladresse prüfen willst, nimm zuerst den einfachen Standardlauf und variiere erst danach die Optionen.
- Öffne Terminal.
- Starte einen ersten Trace mit
traceroute beispiel.de. - Wenn die Standardprobe nur Sterne liefert oder merkwürdig aussieht, teste mit
traceroute -I beispiel.de. - Für einen schnellen Erstcheck kannst du
traceroute -n -q 1 -w 2 beispiel.deprobieren.
Ich arbeite dabei gern in zwei Stufen: erst ohne Zusatzoptionen, dann gezielt mit ICMP oder numerischer Ausgabe. So siehst du schneller, ob das Problem am Ziel, unterwegs oder schon in deiner lokalen Umgebung liegt. Sobald der Trace läuft, zählt aber vor allem das Lesen der Ausgabe.
So liest du die Ausgabe richtig
Die Zeilen in der Ausgabe wirken am Anfang trocken, sind aber ziemlich logisch aufgebaut. Entscheidend sind die Hop-Nummer, die Antwortzeit und die Frage, ob der nächste Knoten überhaupt antwortet. Ein synthetisches Beispiel sieht etwa so aus:
1 10.0.0.1 1.1 ms 1.0 ms 1.2 ms
2 100.64.0.1 8.4 ms 8.2 ms 8.5 ms
3 * * *
4 203.0.113.17 31.4 ms 31.2 ms 31.6 ms| Element | Bedeutung | Was ich daraus ableite |
|---|---|---|
| Hop-Nummer | Reihenfolge der Zwischenstationen | Wo der Weg beginnt und an welcher Stelle die Route auffällig wird |
| Hostname oder IP | Antwortender Router oder Zielsystem | Ob die Namensauflösung sauber ist und welcher Knoten antwortet |
| ms-Werte | Laufzeit der Probes | Ob ein Abschnitt langsam, stabil oder schwankend ist |
* * * |
Keine Antwort innerhalb des Timeouts | Oft Filter, Rate-Limiting oder Verlust, nicht automatisch ein kompletter Ausfall |
| Wechselnde IPs am selben Hop | Mehrere mögliche Wege oder Load Balancing | Die Route ist nicht starr, deshalb einzelne Läufe vorsichtig bewerten |
Wenn ich einen Trace für Support oder Infrastruktur frage, bewerte ich die ersten beiden Hops immer besonders streng: Dort erkenne ich am schnellsten, ob das Problem lokal oder bereits beim Provider sitzt. Genau an dieser Stelle helfen die passenden Optionen, wenn die Standardausgabe noch zu viel Rauschen enthält.
Welche Optionen im Alltag wirklich helfen
Ich benutze nur wenige Schalter regelmäßig. Sie machen die Messung nicht komplizierter, sondern oft klarer.
| Option | Wofür sie gut ist | Mein typischer Einsatz |
|---|---|---|
-I |
Verwendet ICMP statt UDP | Wenn die Standardprobe geblockt wird oder nur Sterne zurückkommen |
-n |
Unterdrückt DNS-Namen | Wenn ich schneller messen oder DNS als Störfaktor ausschließen will |
-q 1 |
Nur eine Probe pro Hop | Für einen schnellen Erstblick, nicht für eine endgültige Analyse |
-w 2 |
Kürzere Wartezeit pro Probe | Wenn ich auf einem unruhigen Netz nicht zu lange pro Hop warten will |
-m 20 |
Begrenzt die maximale Hop-Zahl | Wenn ich nur den relevanten Abschnitt sehen möchte |
-p 33434 |
Ändert den Zielportbereich | Wenn der Standardbereich kollidiert oder gestört wird |
Mein praktischer Favorit für einen ersten Vergleich ist oft traceroute -I -n. Damit entferne ich zwei häufige Störquellen auf einmal: blockierte UDP-Probes und langsame Namensauflösung. Als Nächstes geht es darum, was du tun kannst, wenn der Trace trotzdem unvollständig bleibt.
Wenn nur Sternchen erscheinen
Ein Trace mit vielen Sternchen ist ärgerlich, aber noch kein Beweis für einen kompletten Netzausfall. Router dürfen ICMP-Antworten drosseln oder unterdrücken, Firewalls blockieren bestimmte Probes, und VPNs oder Provider-Grenzen können das Bild zusätzlich verwischen. Ich prüfe deshalb immer zuerst, wo die Sternchen anfangen.
| Symptom | Wahrscheinliche Ursache | Mein nächster Test |
|---|---|---|
| Sterne schon am ersten oder zweiten Hop | Lokaler Router, Firewall oder VPN reagiert nicht auf die Probe |
-I testen, VPN deaktivieren, anderes Netzwerk probieren |
| Erste Hops sauber, danach Sterne | Upstream, Peering oder Transit filtert Antworten | Von einer anderen Leitung erneut messen und Uhrzeit notieren |
| Hop-Abfolge ändert sich zwischen Läufen | Load Balancing oder asymmetrische Wege | Mehrere Läufe vergleichen statt einen einzelnen als Wahrheit zu nehmen |
| Hohe Zeiten an einem einzelnen Hop, danach wieder normal | Der Router antwortet langsam, leitet Daten aber oft trotzdem sauber weiter | Mit ping gegenprüfen und nicht nur auf einen Wert starren |
Besonders in Netzen mit mehreren Übergabepunkten, wie man sie bei Mobilfunk, Glasfaserzugang oder internationalem Transit oft sieht, ist das sauber zu trennen. Deshalb bewerte ich einen schlechten Trace immer als Hinweis, nicht als endgültiges Urteil. Genau daraus ergibt sich der Nutzen für Netzwerk- und Infrastrukturthemen.
Warum traceroute für Netzwerke und Infrastruktur so nützlich ist
Für die Fehleranalyse in Netzen ist traceroute deshalb so wertvoll, weil es aus einem vagen Problem eine räumliche Frage macht: Liegt die Verzögerung noch im eigenen Netz, beim Provider oder erst weiter draußen? In der Praxis hilft mir das gerade dort, wo mehrere Transport- und Übergabestufen ineinandergreifen. Für Konnektivität in Timor-Leste ist dieser Blick besonders hilfreich, weil sich Störungen oft erst an der Grenze zwischen lokalem Zugang, Provider-Übergabe und weiterem Transit sichtbar machen.
| Werkzeug | Antwortet vor allem auf | Wann ich es parallel nutze |
|---|---|---|
ping |
Kommt das Ziel grundsätzlich zurück? | Wenn ich Erreichbarkeit und Grundlatenz prüfen will |
traceroute |
An welcher Stelle der Route wird es auffällig? | Wenn Pfad, Übergaben oder Umwege relevant sind |
dig oder nslookup
|
Wird der Name korrekt aufgelöst? | Wenn der Hostname selbst verdächtig wirkt |
Ich kombiniere diese drei Werkzeuge gern, weil sie zusammen ein vollständigeres Bild liefern: DNS, Erreichbarkeit und Weg. Erst dadurch lässt sich sauber unterscheiden, ob ein Problem technisch im Netz, am Namensdienst oder erst am Zielhost entsteht.
Mit sauberen Messungen bekommst du belastbare Ergebnisse
- Ich starte immer mit einem normalen Lauf und vergleiche danach gezielt mit
-I. - Ich nutze
-n, wenn die Namensauflösung die Ausgabe unnötig verlangsamt. - Ich teste WLAN, VPN und Mobilfunk getrennt, weil sie völlig unterschiedliche Pfade liefern können.
- Ich notiere Uhrzeit, Zielhost und Netzart, wenn ich den Trace weitergeben will.
- Ich verlasse mich nie auf nur einen Lauf, wenn die Verbindung schwankt.
Mein pragmatischer Standard ist simpel: erst ohne Zusatzoptionen testen, dann mit -I, danach bei Bedarf mit -n, kürzerem Timeout und einem zweiten Netz gegenprüfen. So wird aus einem einzigen Mac-Befehl ein brauchbares Bild darüber, ob das Problem lokal, beim Provider oder erst weiter außen im Netz sitzt. Wenn du diese Reihenfolge einhältst, liest du traceroute nicht nur, sondern nutzt es wie ein echtes Diagnosewerkzeug.